

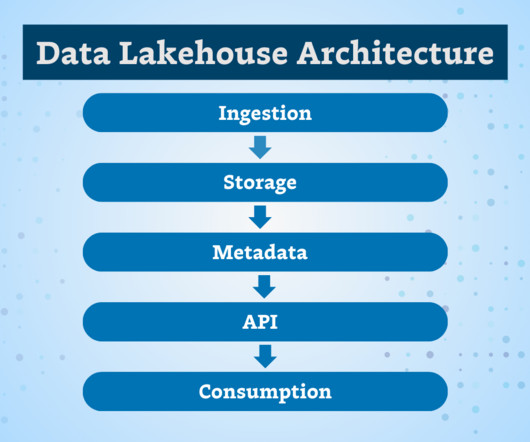
Eliminate Friction In Your Data Platform Through Unified Metadata Using OpenMetadata
Data Engineering Podcast
NOVEMBER 10, 2021
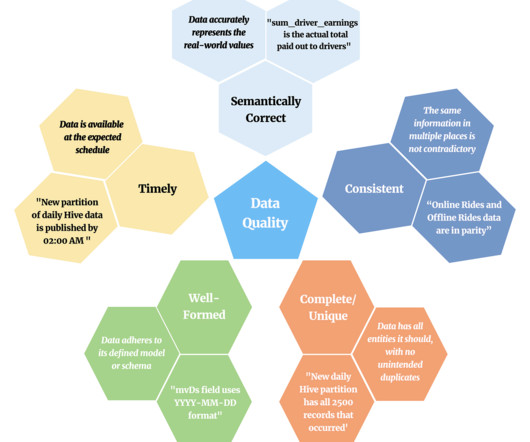
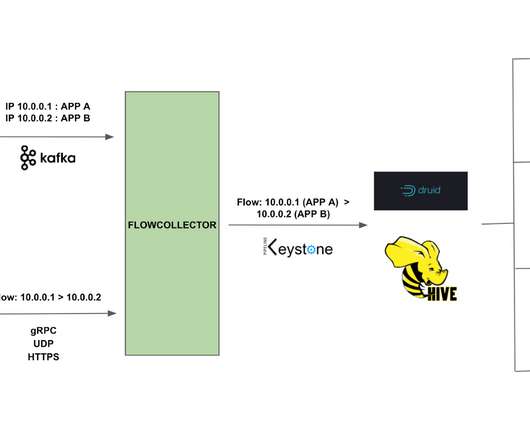
Summary A significant source of friction and wasted effort in building and integrating data management systems is the fragmentation of metadata across various tools. After experiencing the impacts of fragmented metadata and previous attempts at building a solution Suresh Srinivas and Sriharsha Chintalapani created the OpenMetadata project.






































Let's personalize your content