This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
It leverages knowledge graphs to keep track of all the data sources and data flows, using AI to fill the gaps so you have the most comprehensive metadata management solution. Together, Cloudera and Octopai will help reinvent how customers manage their metadata and track lineage across all their data sources.
Metadata is the data providing context about the data, more than what you see in the rows and columns. By managing your metadata, you're effectively creating an encyclopedia of your data assets.
Summary Metadata is the lifeblood of your data platform, providing information about what is happening in your systems. In order to level up their value a new trend of active metadata is being implemented, allowing use cases like keeping BI reports up to date, auto-scaling your warehouses, and automated data governance.
Metadata: Information about pipeline runs, & data flowing through your pipeline 3.2. Introduction 2. Setup & Logging architecture 3. Data Pipeline Logging Best Practices 3.1. Obtain visibility into the code’s execution sequence using text logs 3.3. Understand resource usage by tracking Metrics 3.4.
Results are stored in git and their database, together with benchmarking metadata. Benchmarking results for each instance type are stored in sc-inspector-data repo, together with the benchmarking task hash and other metadata. There Then we wait for the actual data and/or final metadata (e.g.
While data products may have different definitions in different organizations, in general it is seen as data entity that contains data and metadata that has been curated for a specific business purpose. A data fabric weaves together different data management tools, metadata, and automation to create a seamless architecture.
Iceberg tables become interoperable while maintaining ACID compliance by adding a layer of metadata to the data files in a users object storage. An external catalog tracks the latest table metadata and helps ensure consistency across multiple readers and writers. Put simply: Iceberg is metadata.
These include attributes of the action itself (such as locale, time, duration, and device type) as well as information about the content (such as item ID and metadata like genre and release country). Therefore, its also important to let foundation models use metadata information of entities and inputs, not just member interaction data.
Moreover, we anticipate a growing emphasis on intelligent data platforms that unify data and metadata, further supported by efforts to enhance data cataloging and lineage tracking. Data quality and privacy remain at the forefront, especially as AI applications demand fresh and accurate data.
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. This is Croissant. Starting today it will be supported by 3 majors platforms: Kaggle, HuggingFace and OpenML.
Product matching is an essential function in many retail and consumer goods organizations. Incoming products are compared to items in the existing product.
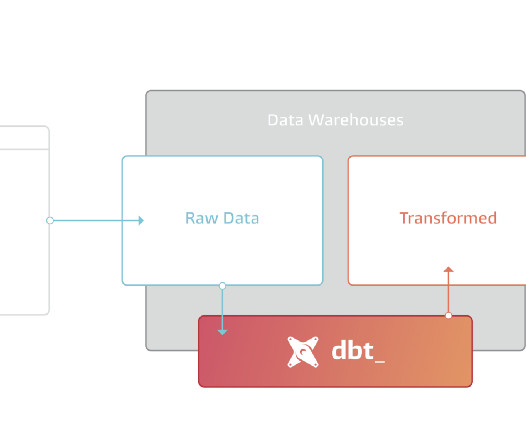
You can also add metadata on models (in YAML). docs — in dbt you can add metadata on everything, some of the metadata is already expected by the framework and thank to it you can generate a small web page with your light catalog inside: you only need to do dbt docs generate and dbt docs serve.
In this case, the main stakeholders are: - Title Launch Operators Role: Responsible for setting up the title and its metadata into our systems. TitleSetup A titles setup includes essential attributes like metadata (e.g., This structured approach allows us to address all aspects of title health comprehensively.
In the realm of modern analytics platforms, where rapid and efficient processing of large datasets is essential, swift metadata access and management are critical for optimal system performance. Any delays in metadata retrieval can negatively impact user experience, resulting in decreased productivity and satisfaction. What is Atlas?
Did someone say Metadata? There are even folks who create dashboards from this metadata to help other engineers identify expensive copying, use of inefficient or inappropriate C++ containers, overuse of smart pointers, and much more. Looking at function call stacks with flame graphs is great, nothing against it.
In August, we wrote about how in a future where distributed data architectures are inevitable, unifying and managing operational and business metadata is critical to successfully maximizing the value of data, analytics, and AI. It is a critical feature for delivering unified access to data in distributed, multi-engine architectures.
This ecosystem includes: Catalogs: Services that manage metadata about Iceberg tables (e.g., Maintenance Processes: Operations that optimize Iceberg tables, such as compacting small files and managing metadata. Metadata Overhead: Iceberg relies heavily on metadata to track table changes and enable features like time travel.
Below a diagram describing what I think schematises data platforms: Data storage — you need to store data in an efficient manner, interoperable, from the fresh to the old one, with the metadata. It adds metadata, read, write and transactions that allow you to treat a Parquet file as a table. That's why you need a catalog.
This approach is exemplified in the following code snippet: During runtime execution, Privacy Probes does the following: Capturing payloads : It captures source and sink payloads in memory on a sampled basis, along with supplementary metadata such as event timestamps, asset identifiers, and stack traces as evidence for the data flow.
In this blog, well address this challenge by building a metadata-driven solution using a JavaScript stored procedure that dynamically maps and loads only the required columns from multiple CSV files into their respective Snowflake tables. Metadata Proc Step 4: Execute the Stored Procedure.
Canva writes about its custom solution using dbt and metadata capturing to attribute costs, monitor performance, and enable data-driven decision-making, significantly enhancing its Snowflake environment management. link] JBarti: Write Manageable Queries With The BigQuery Pipe Syntax Our quest to simplify SQL is always an adventure.
what kinds of questions are you answering with table metadata what use case/team does that support comparative utility of iceberg REST catalog What are the shortcomings of Trino and Iceberg? What were the requirements and selection criteria that led to the selection of that combination of technologies?
To tackle the problem, we attach a piece of model version metadata to each ANN search service host, which contains a mapping from model name to the latest model version. The metadata is generated together with the index.
Focus on metadata management. As Yoğurtçu points out, “metadata is critical” for driving insights in AI and advanced analytics. “Large language models are excellent at inferring hidden relationships and context,” says Anandarajan.
Orchestration is now a part of most vertical tools Cloud data warehouses Data lakes DataOps and MLOps Data quality to data observability Metadata for everything Data catalog -> data discovery -> active metadata Business intelligence Read only reports to metric/semantic layers Embedded analytics and data APIs Rise of ELT dbt Corresponding introduction (..)
Automated metadata management – AI-generated catalog asset descriptions significantly reduce manual efforts and improve metadata quality – enabling teams to focus on more strategic tasks. With the ability to turn functionality on or off based on business requirements, you gain full control over when and how AI is applied.
Overall, data must be easily accessible to AI systems, with clear metadata management and a focus on relevance and timeliness. And data strategy must evolve to make sure that AI initiatives are aligned with business goals and are effectively instilling a data-driven culture in the organization.
This logic consists of the following parts: DDL code, table metadata information, data transformation and a few audit steps. DDL Often, the first step in a data pipeline is to define the target table structure and column metadata via a DDL statement. For the workflow orchestration we use Netflix homegrown Maestro scheduler.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
Meanwhile, operations teams use entity extraction on documents to automate workflows and enable metadata-driven analytical filtering. Customer intelligence teams analyze reviews and forum comments to identify sentiment trends, while support teams process tickets to uncover product issues and inform gaps in a product roadmap.
It could be metadata that you weren’t capturing before. And the value of the 10% is as much as the 85% and as much as the next 5% to get to 95%. To get to a full 100%, that last 5% is even more valuable. That’s context, that’s location. That’s anything from perspiration to heart rate it’s all being captured.
That is done via a careful examination of all metadata repositories describing data sources. Once those repositories have been carefully studied, the identified data sources must be scanned by a data catalog, so that a metadata mirror of these data sources are made discoverable for the operations team.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
Metadata catalog stores information about datasets 3.1.3. Most platforms enable you to do the same thing but have different strengths 3.1. Understand how the platforms process data 3.1.1. A compute engine is a system that transforms data 3.1.2. Data platform support for SQL, Dataframe, and Dataset APIs 3.1.4.
Better Metadata Management Add Descriptions and Data Product tags to tables and columns in the Data Catalog for improved governance. Smarter Profiling & Test Generation Improved logic reduces false positives , making test results more accurate and actionable. DataOps just got more intelligent.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. From analyzing your metadata, query logs, and dashboard activities, Select Star will automatically document your datasets.
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan’s active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don’t forget to thank them for their continued support of this show!
Atlan is the metadata hub for your data ecosystem. Instead of locking your metadata into a new silo, unleash its transformative potential with Atlan's active metadata capabilities. Atlan is the metadata hub for your data ecosystem. And don't forget to thank them for their continued support of this show!
Then, we add another column called HASHKEY , add more data, and locate the S3 file containing metadata for the iceberg table. Hence, the metadata files record schema and partition changes, enabling systems to process data with the correct schema and partition structure for each relevant historical dataset.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.

















































Let's personalize your content