
A Definitive Guide to Using BigQuery Efficiently
Towards Data Science
MARCH 5, 2024
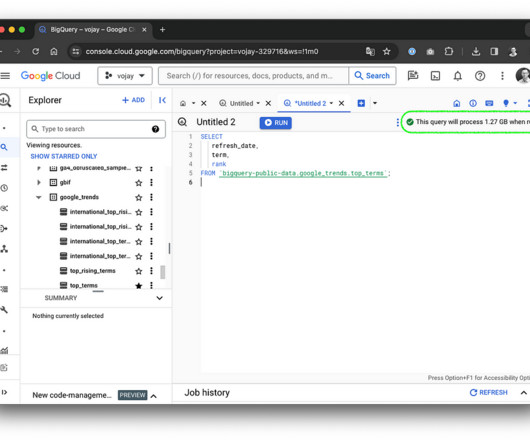
Like a dragon guarding its treasure, each byte stored and each query executed demands its share of gold coins. Join as we journey through the depths of cost optimization, where every byte is a precious coin. It is also possible to set a maximum for the bytes billed for your query. Photo by Konstantin Evdokimov on Unsplash ?





































Let's personalize your content