This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
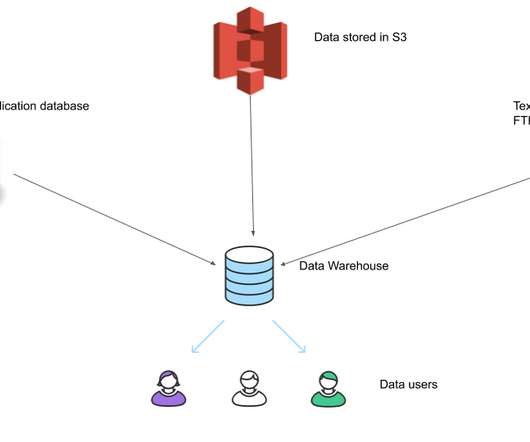
Intro A very common use case in data engineering is to build a ETLsystem for a data warehouse, to have data loaded in from multiple separate databases to enable data analysts/scientists to be able to run queries on this data, since the source databases are used by your applications and we do not want these analytic queries to affect our application (..)
A natural outgrowth of that capability is the more recent growth of reverse ETLsystems that use those analytics to feed back into the operational systems used to engage with the customer. In this episode Tejas Manohar and Rachel Bradley-Haas share the story of their own careers and experiences coinciding with these trends.
If you’re a data engineering podcast listener, you get credits worth $3000 on an annual subscription Your host is Tobias Macey and today I’m interviewing Brian Leonard about Grouparoo, an open source framework for managing your reverse ETL pipelines Interview Introduction How did you get involved in the area of data management?
ETL testing can be challenging since most ETLsystems process large volumes of heterogeneous data. However, establishing clear requirements from the start can make it easier for ETL testers to perform the required tests. Stages of the ETL Testing Process The ETL testing process can be broken down into 8 different stages.
How to Fit Reverse ETL Into Your Data Architecture Once businesses comprehend the advantages of reverse ETL, the question often is whether you should buy a reverse ETL solution or use your data team to build one for your company. First, building your custom reverse ETLsystem is more expensive than you think.
Reason Two: Handle Big Data Efficiently The emergence of needs and tools of ETL proceeded the Big Data era. As data volumes continued to grow in the traditional ETLsystems, it required a proportional increase in the people, skills, software and resources.
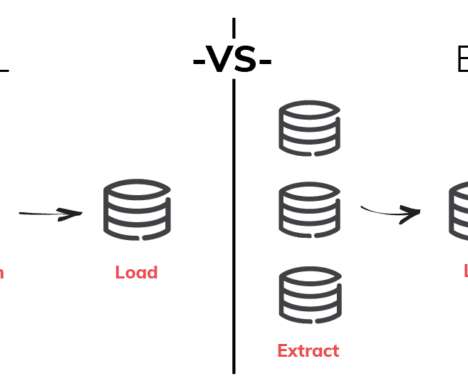
An ETL data pipeline extracts raw data from a source system, transforms it into a structure that can be processed by a target system, and loads the transformed data into the target, usually a database or data warehouse While the terms “data pipeline” and ETL are often used interchangeably, there are some key differences between the two.
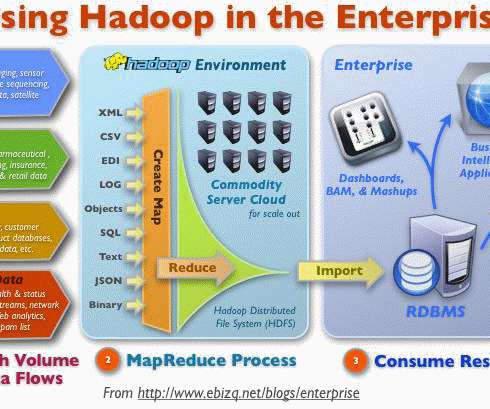
A lot of organizations are moving to Spark as their ETL processing layer from legacy ETLsystems like Informatica. Spark is a very good and optimized SQL processing module that fits the ETL requirements as it can read from multiple sources and can also write to many kinds of data sources.
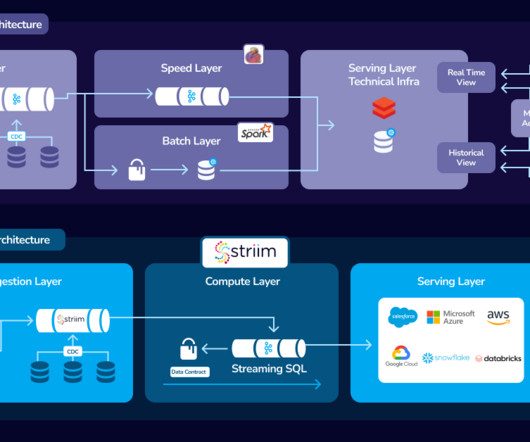
In conclusion, kappa architectures have revolutionized the way businesses approach big data solutions – allowing them to take advantage of cutting edge technologies while reducing costs associated with manual processes like ETLsystems.
The Long Road from Batch to Real-Time Traditional “extract, transform, load” (ETL) systems were built under certain constraints, stemming from the cost of technology and implementation resources, as well as the inherent limits of computational power. Today’s world calls for a streaming-first approach.
In a use case like online ticketing, it may seem obvious that the transactional side of the system is well suited to an event processing architecture, but certain of the analytical requirements demand the same architecture.
An effective ETLsystem should also be designed to ingest data from potentially many different sources. The data storage platform you choose should be optimized to work effectively within your organization's budget constraints. After designing and setting up your database or data warehouse, you need to populate it with data.
Incremental Extraction Each time a data extraction process runs (such as an ETL pipeline), only new data and data that has changed from the last time are collected—for example, collecting data through an API. Transform All the data science professionals would be familiar with the term "Garbage in, garbage out."
Oftentimes these ETLsystems come under considerable pressure as all of your stakeholders want to look at every metric a million different ways with sub second latency. It’s hard to convince departments to launch experiments or executives to trust them if no one believes in the underlying data or the dashboards they look at every day.
Oftentimes these ETLsystems come under considerable pressure as all of your stakeholders want to look at every metric a million different ways with sub second latency. It’s hard to convince departments to launch experiments or executives to trust them if no one believes in the underlying data or the dashboards they look at every day.
Oftentimes these ETLsystems come under considerable pressure as all of your stakeholders want to look at every metric a million different ways with sub second latency. It’s hard to convince departments to launch experiments or executives to trust them if no one believes in the underlying data or the dashboards they look at every day.
We organize all of the trending information in your field so you don't have to. Join 37,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


















Let's personalize your content