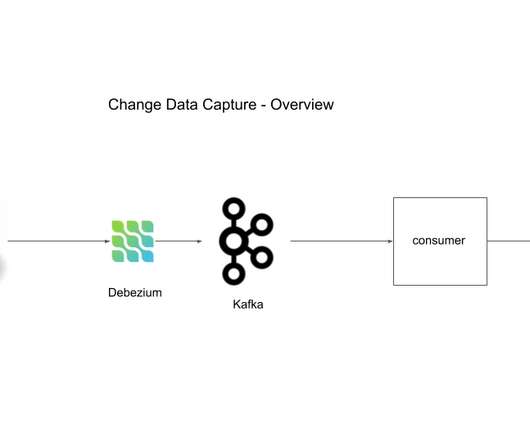
Change Data Capture Using Debezium Kafka and Pg
Start Data Engineering
MAY 9, 2020
Change data capture is a software design pattern used to capture changes to data and take corresponding action based on that change. The change to data is usually one of read, update or delete. The corresponding action usually is supposed to occur in another system in response to the change that was made in the source system.





























Let's personalize your content