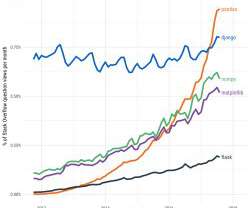
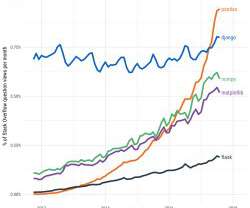
Open Source Projects by Google, Uber and Facebook for Data Science and AI
KDnuggets
NOVEMBER 28, 2019
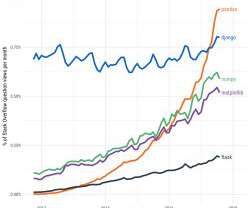
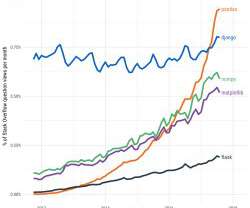
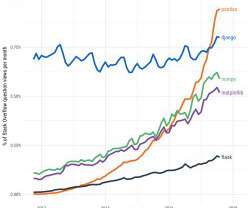
Open source is becoming the standard for sharing and improving technology. Some of the largest organizations in the world namely: Google, Facebook and Uber are open sourcing their own technologies that they use in their workflow to the public.



























Let's personalize your content