

Data Ingestion Azure Data Factory Simplified 101
Hevo
JUNE 20, 2024
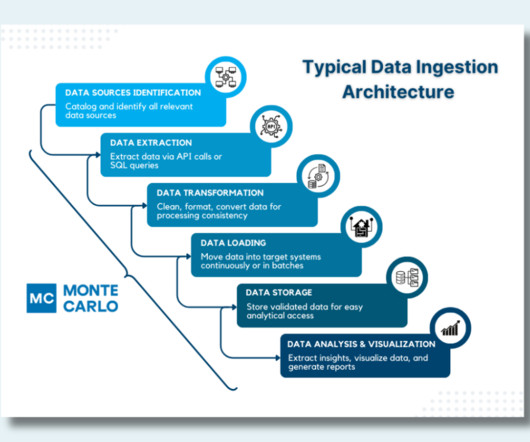
As data collection within organizations proliferates rapidly, developers are automating data movement through Data Ingestion techniques. However, implementing complex Data Ingestion techniques can be tedious and time-consuming for developers.









































Let's personalize your content