

Unlocking Real-Time Mainframe Data Replication with the Precisely Data Integrity Suite and Confluent Data Streams
Precisely
JULY 21, 2023
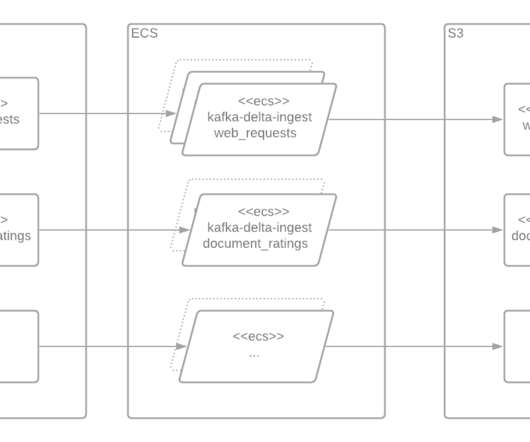
Used by more than 75% of the Fortune 500, Apache Kafka has emerged as a powerful open source data streaming platform to meet these challenges. But harnessing and integrating Kafka’s full potential into enterprise environments can be complex. This is where Confluent steps in.




















Let's personalize your content