

On-Premise vs Cloud: Where Does the Future of Data Storage Lie?
Monte Carlo
AUGUST 15, 2023
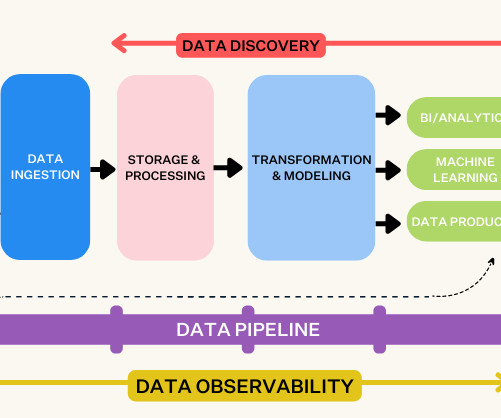
Regardless, the important thing to understand is that the modern data stack doesn’t just allow you to store and process bigger data faster, it allows you to handle data fundamentally differently to accomplish new goals and extract different types of value. It’s just a matter of picking a flavor.











































Let's personalize your content