

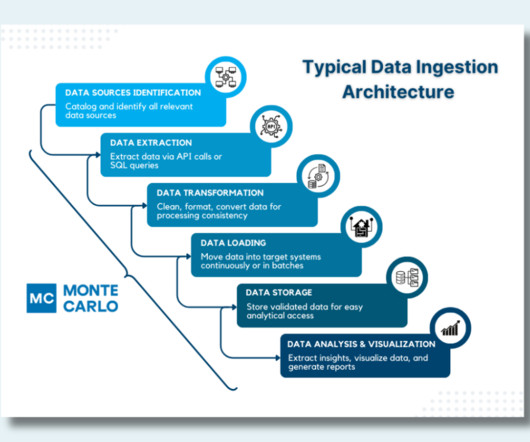
How to Use Kafka for Event Streaming in a Microservices Architecture?
Workfall
JUNE 27, 2023
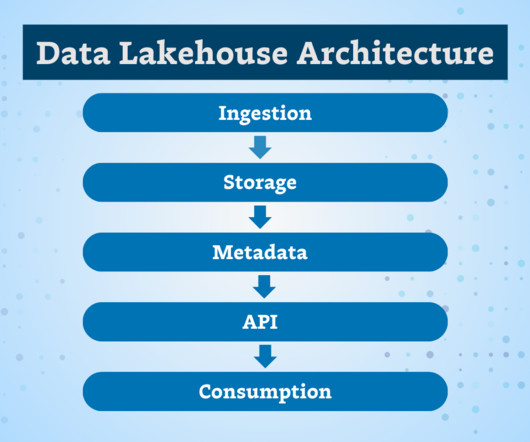
It means that there is a high risk of data loss but Apache Kafka solves this because it is distributed and can easily scale horizontally and other servers can take over the workload seamlessly. It offers a unified solution to real-time data needs any organisation might have. This is where Apache Kafka comes in.











































Let's personalize your content