

Data News — Week 24.11
Christophe Blefari
MARCH 15, 2024
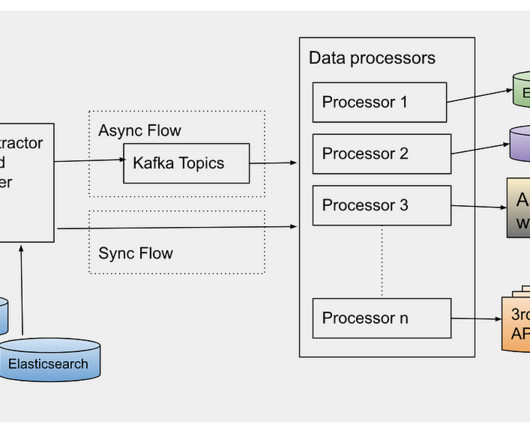
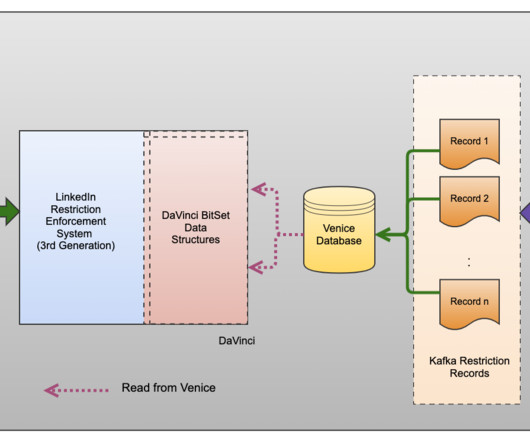
Attributing Snowflake cost to whom it belongs — Fernando gives ideas about metadata management to attribute better Snowflake cost. Obviously Benoit prefers Kestra, at the expense of writing YAML and running a Java application. Unlocking Kafka's potential: tackling tail latency with eBPF. This is Croissant.











































Let's personalize your content