

The fancy data stack—batch version
Christophe Blefari
AUGUST 4, 2023
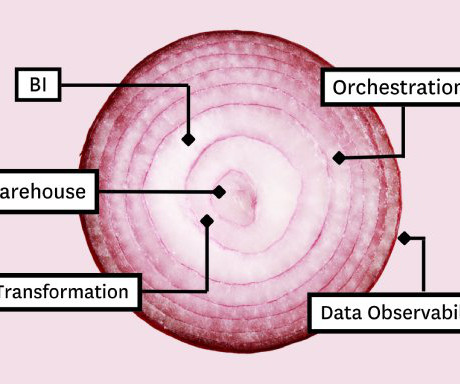
As a disclaimer, this may not quite make sense in a corporate context, but since this is my blog, I'll do what I want. A few requirements The source data lies in Postgres database, in flat CSV and in Google Sheets. A few requirements The source data lies in Postgres database, in flat CSV and in Google Sheets.







































Let's personalize your content