


Data News — Week 24.15
Christophe Blefari
APRIL 12, 2024
I've shared my journey with Apache Superset and why I consider Superset the best open-source alternative when it comes to building BI applications. Yes because you should stop building dashboard and build BI apps instead. In today's edition we have a large selection of links, I think you will enjoy it.































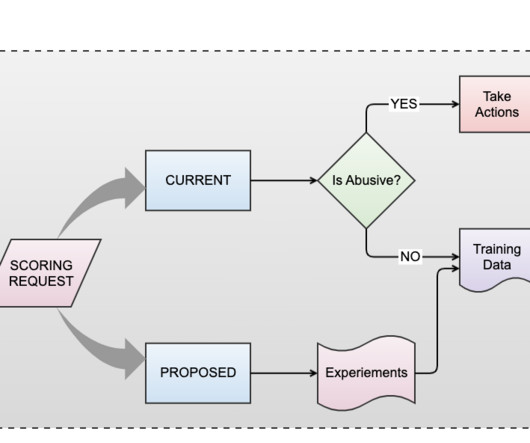
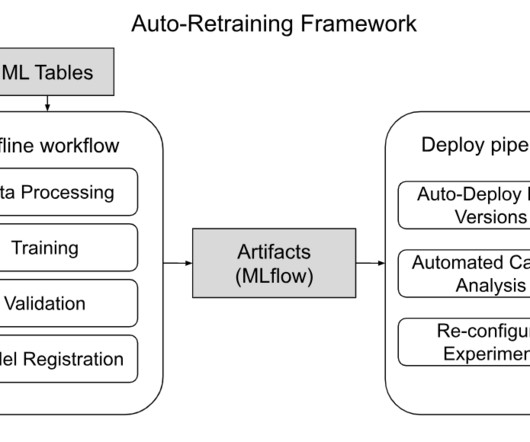

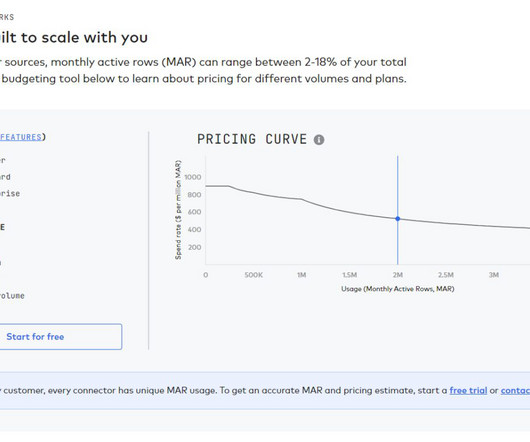



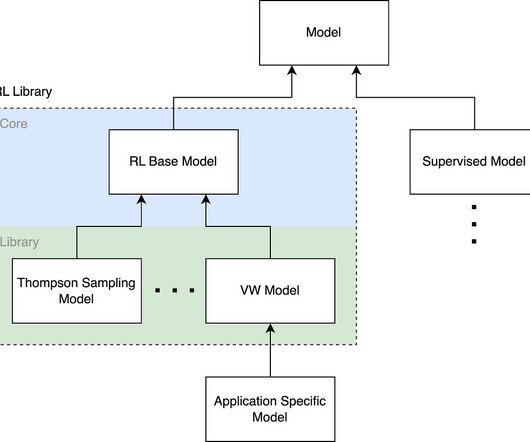






Let's personalize your content