


4x Faster Search Query Performance with Rockset’s Row Store Cache
Rockset
SEPTEMBER 19, 2023
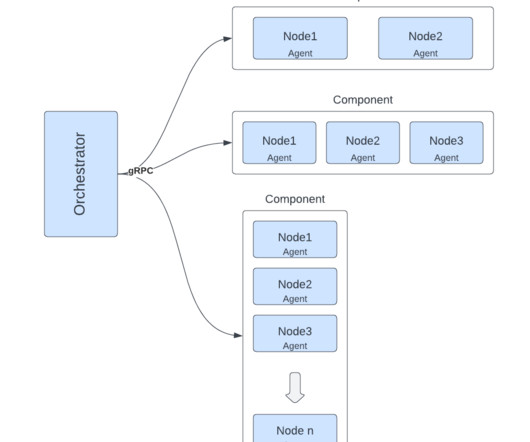
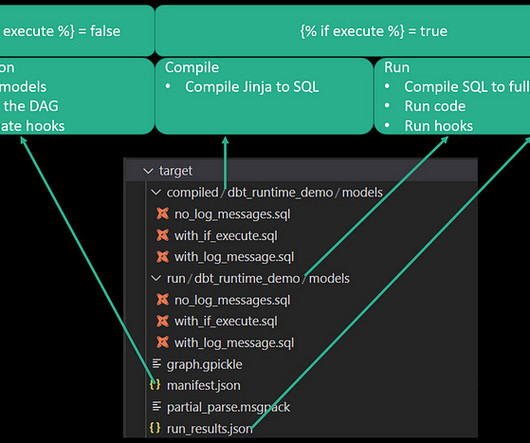
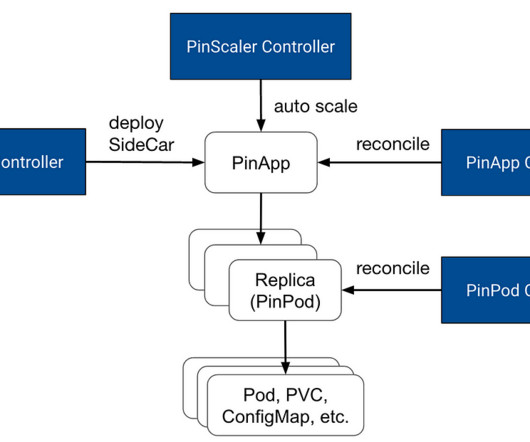
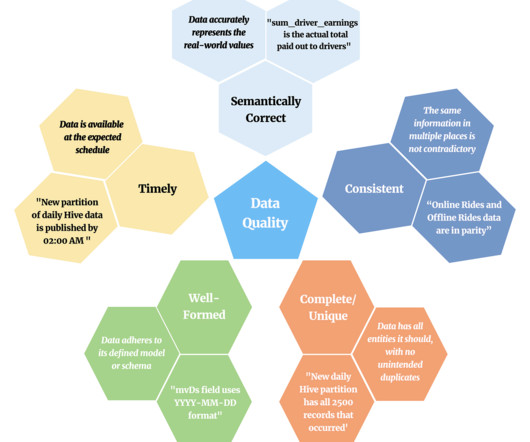
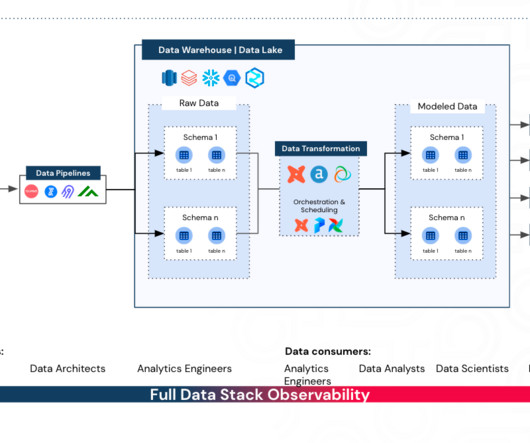
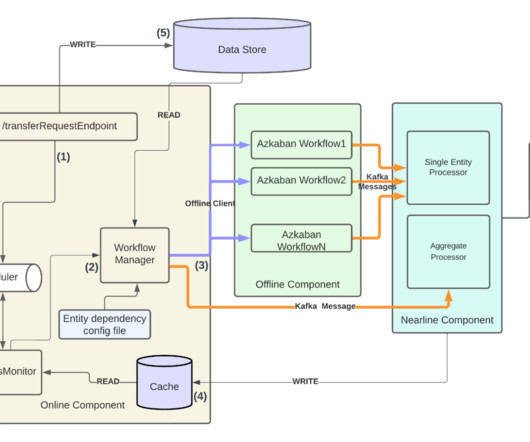
In this blog post we will talk about how we made this step much faster, yielding a 4x speedup for customers' search-like queries. This blog presents how we improved the performance of search query CPU utilization and latency by analyzing search-related workloads and query patterns. These blocks contain multiple key-value pairs.


































Let's personalize your content