


Upgrade your Modern Data Stack
Christophe Blefari
SEPTEMBER 28, 2023
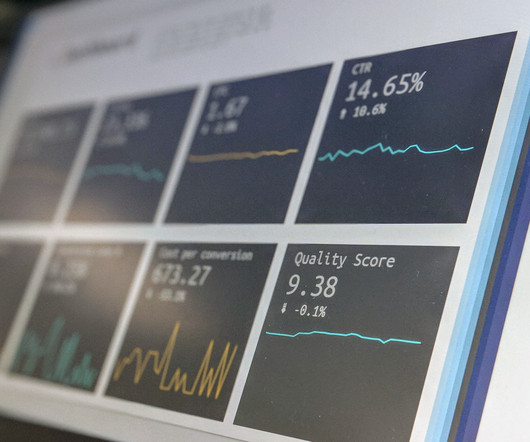
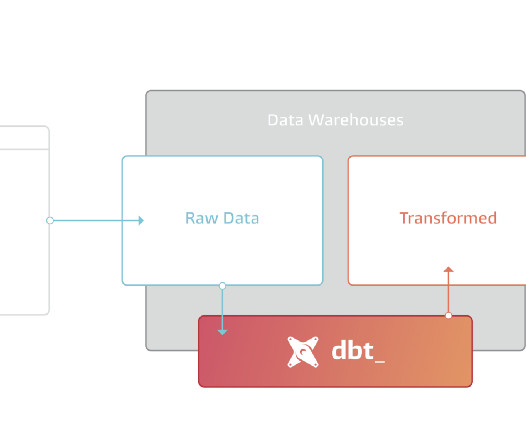
We jumped from HDFS to Cloud Storage (S3, GCS) for storage and from Hadoop, Spark to Cloud warehouses (Redshift, BigQuery, Snowflake) for processing. Historically, data pipelines were designed with an ETL approach, storage was expensive and we had to transform the data before using it. Is the modern data stack dying?










































Let's personalize your content