

What is Real-time Data Ingestion? Use cases, Tools, Infrastructure
Knowledge Hut
JULY 3, 2023
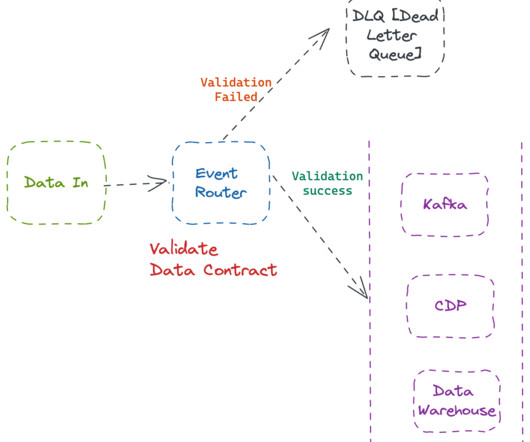
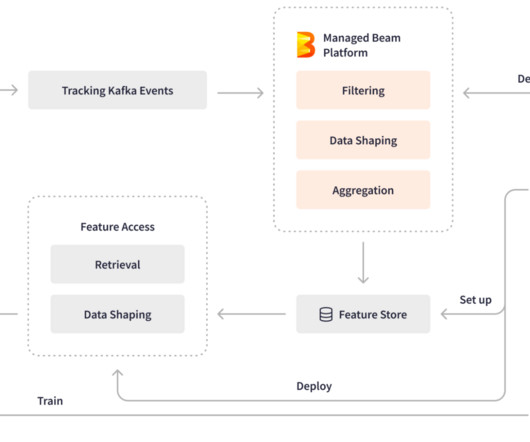
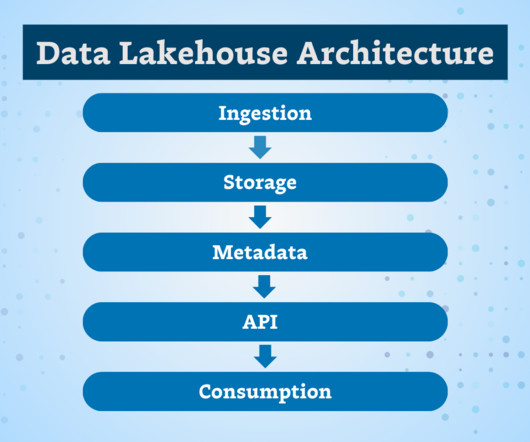
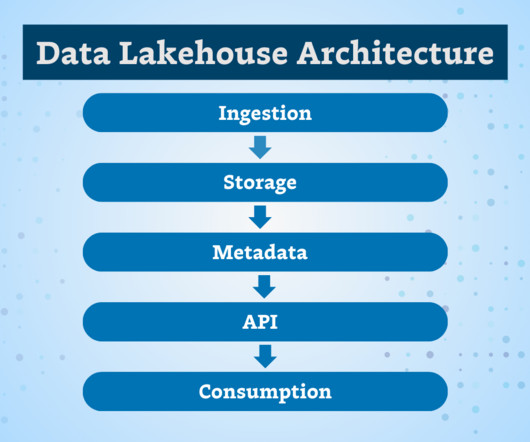
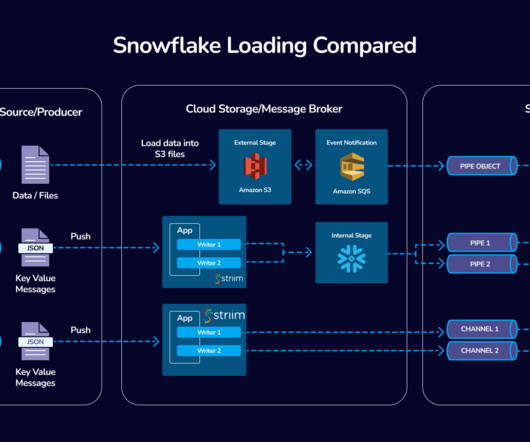
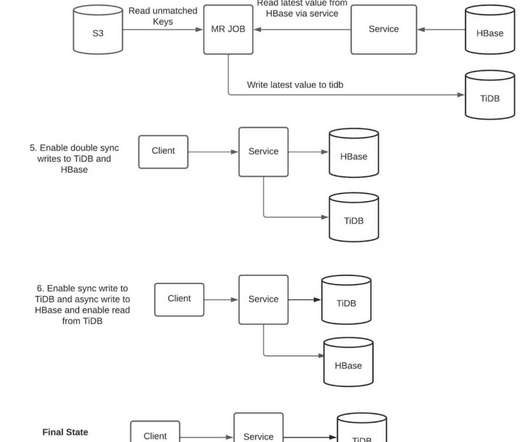
This is where real-time data ingestion comes into the picture. Data is collected from various sources such as social media feeds, website interactions, log files and processing. This refers to Real-time data ingestion. To achieve this goal, pursuing Data Engineer certification can be highly beneficial.








































Let's personalize your content