Multiple Stateful Operators in Structured Streaming
databricks
AUGUST 6, 2023
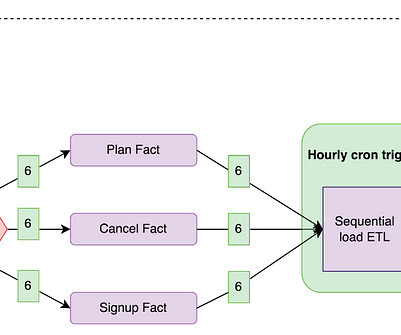
In the world of data engineering, there are operations that have been used since the birth of ETL. You filter.

 multiple-stateful-operators-structured-streaming Blog Related Topics
multiple-stateful-operators-structured-streaming Blog Related Topics 
databricks
AUGUST 6, 2023
In the world of data engineering, there are operations that have been used since the birth of ETL. You filter.

Cloudera
JUNE 2, 2022
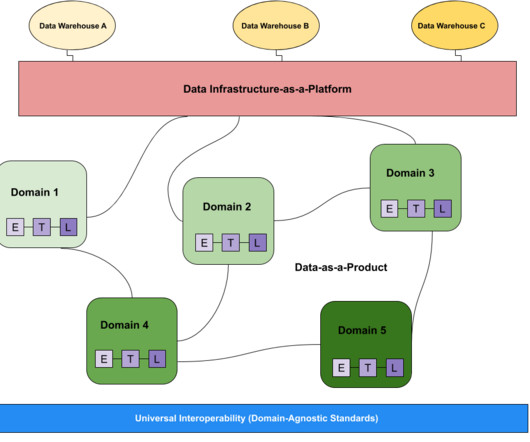
Over the last few years, we have had a front-row seat in our customers’ hybrid cloud journey as they expand their data estate across the edge, on-premise, and multiple cloud providers. allowing developers to connect to any data source anywhere with any structure, process it, and deliver to any destination.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Cloudera
FEBRUARY 23, 2023
Every day in the US thousands of legitimate prescriptions for the opioid class of pharmaceuticals are written to mitigate acute pain during post-operation recovery, chronic back and neck pain, and a host of other cases where patients experience moderate-to-severe discomfort. This epidemic affects more than just individuals.
Netflix Tech
NOVEMBER 14, 2023
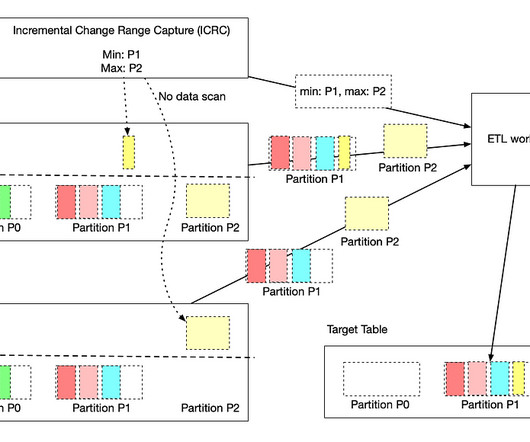
In this three-part blog post series, we introduce you to Psyberg , our incremental data processing framework designed to tackle such challenges! At Netflix, our backend microservices continuously generate real-time event data that gets streamed into Kafka. Given our role on this critical path, accuracy is paramount.

Pinterest Engineering
SEPTEMBER 29, 2023
Sanchay Javeria | Software Engineer, Ads Data Infrastructure To support metrics reporting for ads from external advertisers and real-time ad budget calculations at Pinterest, we run streaming pipelines using Apache Flink. Framework off-heap memory is reserved for Flink’s internal operations and data structures.

Databand.ai
AUGUST 30, 2023
A DataOps architecture is the structural foundation that supports the implementation of DataOps principles within an organization. Data sources can be structured or unstructured, and they can reside either on-premises or in the cloud.

Cloudera
SEPTEMBER 30, 2022
CDF-PC enables organizations to take control of their data flows and eliminate ingestion silos by allowing developers to connect to any data source anywhere with any structure, process it, and deliver to any destination using a low-code authoring experience. build high performant, scalable web applications across multiple data centers).

Expert insights. Personalized for you.






























Let's personalize your content