
What Are the Best Data Modeling Methodologies & Processes for My Data Lake?
phData: Data Engineering
SEPTEMBER 19, 2023
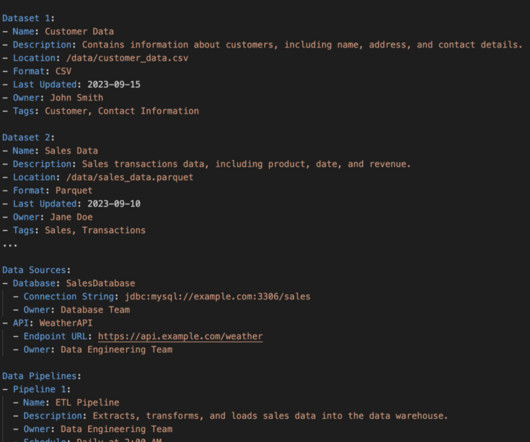
Data lakes have emerged as a popular solution, offering the flexibility to store and analyze diverse data types in their raw format. However, to fully harness the potential of a data lake, effective data modeling methodologies and processes are crucial. Consistency of data throughout the data lake.








































Let's personalize your content