
Metadata Management and Data Governance with Cloudera SDX
Cloudera
JANUARY 26, 2024
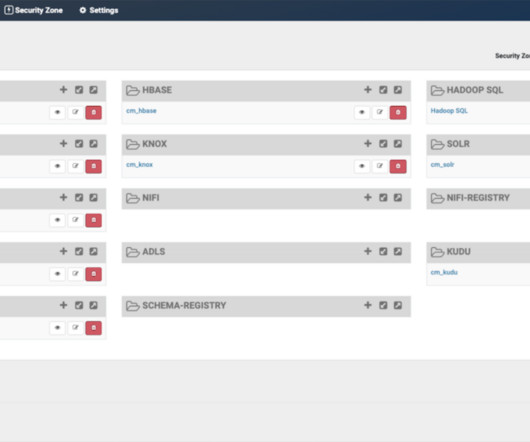
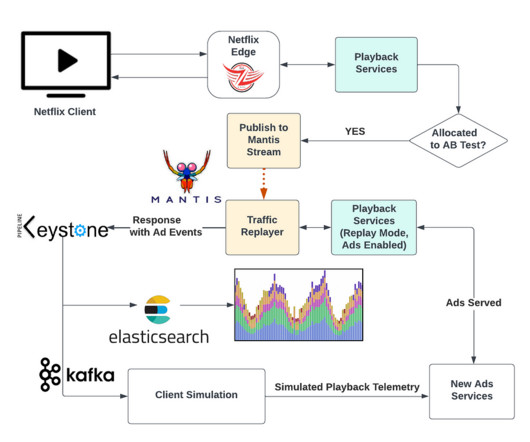
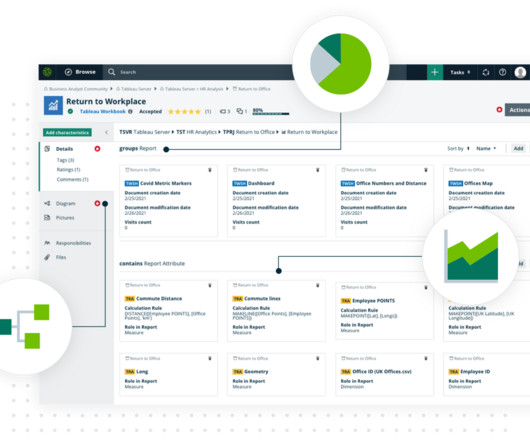
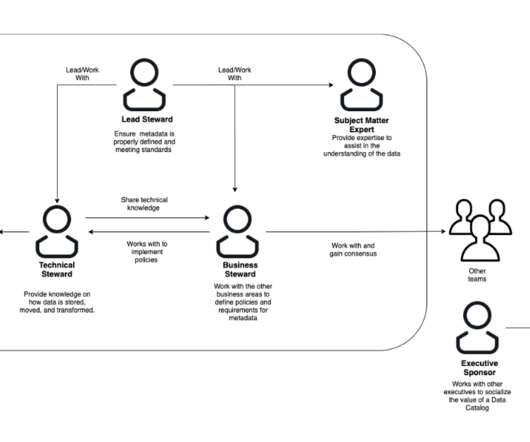
In this article, we will walk you through the process of implementing fine grained access control for the data governance framework within the Cloudera platform. Case Introduction In this article we will take the example of a data governance office that wants to control access to metadata objects in the company’s central data repository.































Let's personalize your content