
Open-Sourcing AvroTensorDataset: A Performant TensorFlow Dataset For Processing Avro Data
LinkedIn Engineering
JUNE 15, 2023
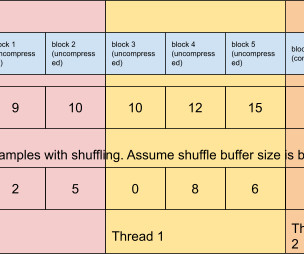
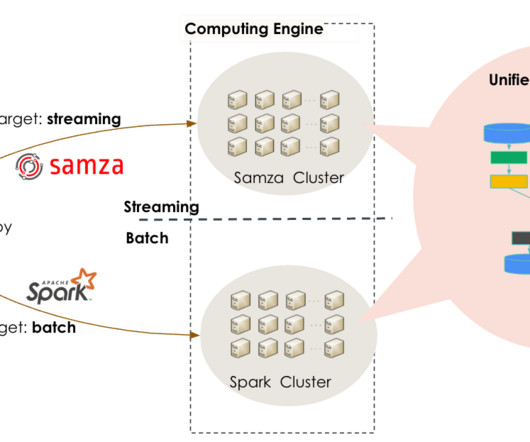
To remove this bottleneck, we built AvroTensorDataset , a TensorFlow dataset for reading, parsing, and processing Avro data. AvroTensorDataset speeds up data preprocessing by multiple orders of magnitude, enabling us to keep site content as fresh as possible for our members. avro", "part-00001.avro"],











































Let's personalize your content