


Anomaly Detection using Sigma Rules (Part 4): Flux Capacitor Design
Towards Data Science
MARCH 1, 2023
We implement a Spark structured streaming stateful mapping function to handle temporal proximity correlations in cyber security logs Image by Robert Wilson from Pixabay This is the 4th article of our series. In this article, we will detail the design of a custom Spark flatMapWithGroupState function.












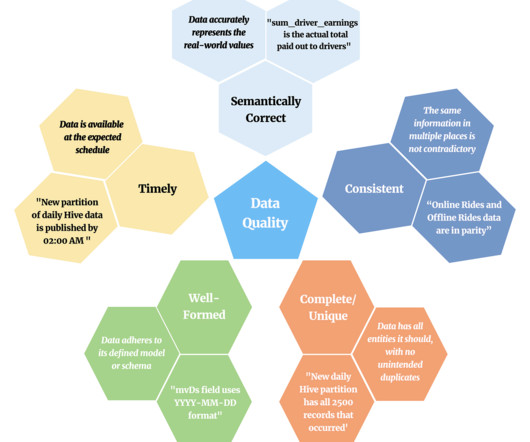

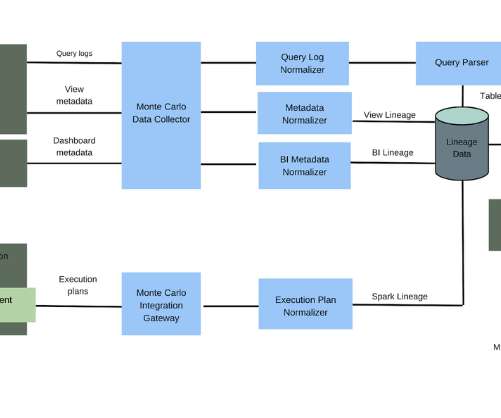















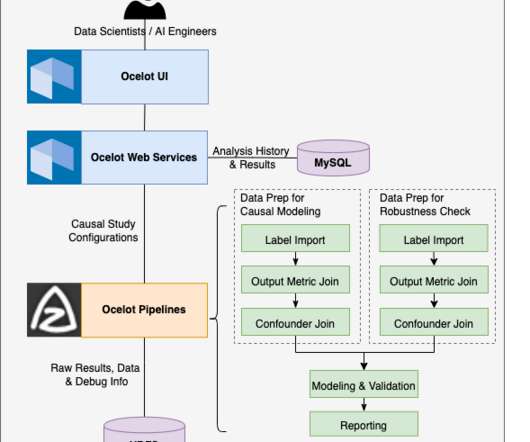












Let's personalize your content