

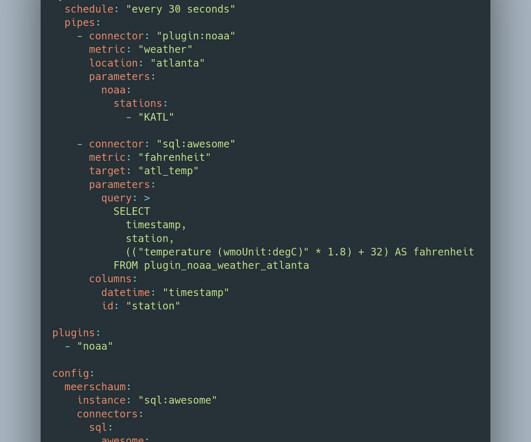
The Docker Compose of ETL: Meerschaum Compose
Towards Data Science
JUNE 19, 2023
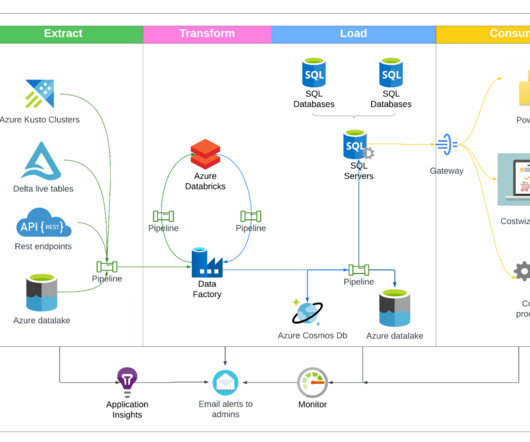
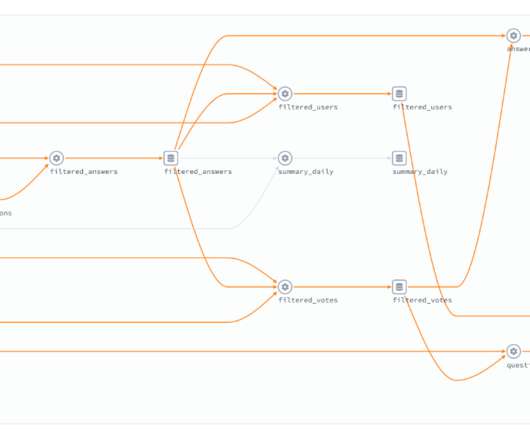
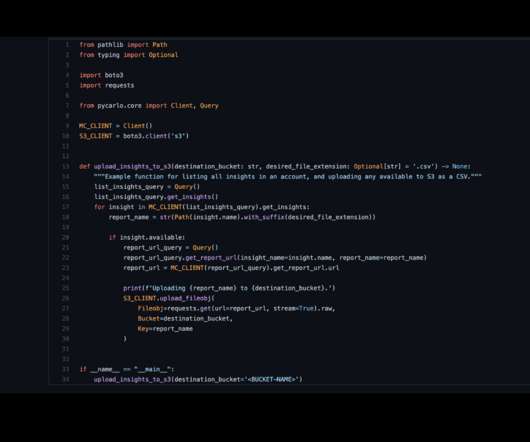
Photo by CHUTTERSNAP on Unsplash This article is about Meerschaum Compose , a tool for defining ETL pipelines in YAML and a plugin for the data engineering framework Meerschaum. In a similar vein, this issue of consistent environments also emerged for the ETL framework Meerschaum. Note: Compose will tag pipes with the project name.







































Let's personalize your content