

Data News — Week 22.45
Christophe Blefari
NOVEMBER 11, 2022
Modeling is often lead by the dimensional modeling but you can also do 3NF or data vault. When it comes to storage it's mainly a row-based vs. a column-based discussion, which in the end will impact how the engine will process data. The end-game dataset. This is probably the concept I liked the most from the video.







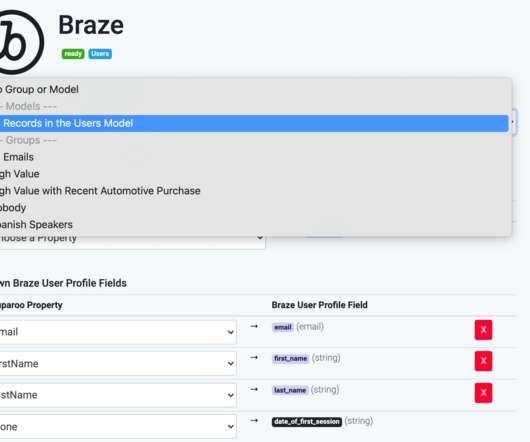














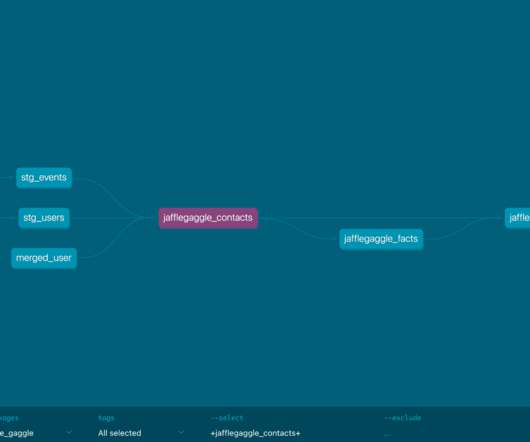



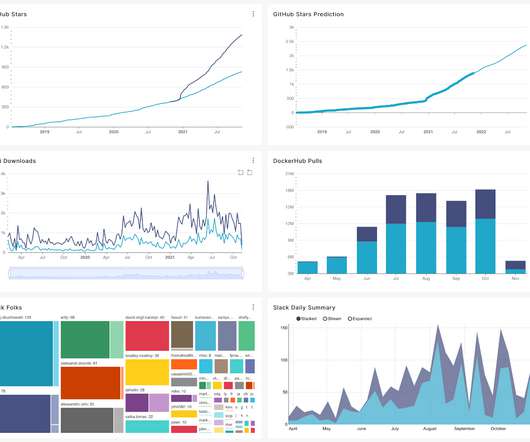
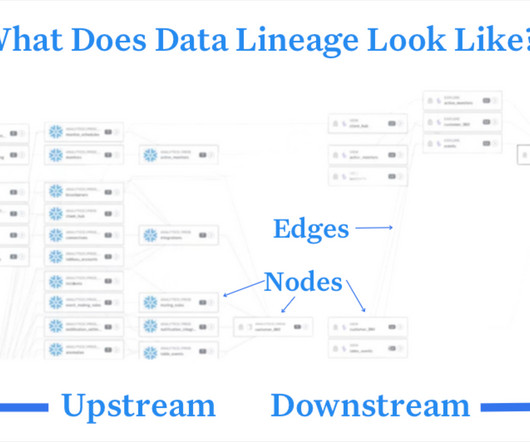












Let's personalize your content