
OLAP vs. OLTP: A Comparative Analysis of Data Processing Systems
KDnuggets
AUGUST 21, 2023
A comprehensive comparison between OLAP and OLTP systems, exploring their features, data models, performance needs, and use cases in data engineering.

KDnuggets
AUGUST 21, 2023
A comprehensive comparison between OLAP and OLTP systems, exploring their features, data models, performance needs, and use cases in data engineering.

Netflix Tech
MARCH 7, 2024
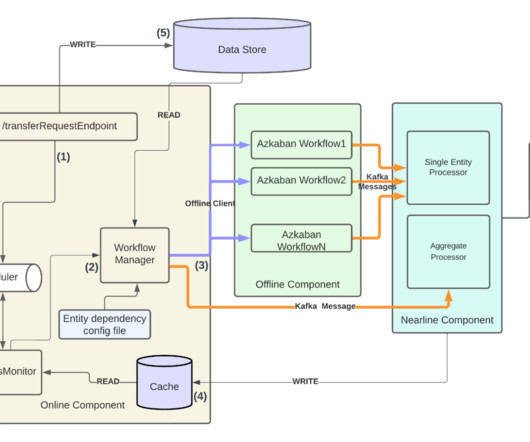
The Machine Learning Platform (MLP) team at Netflix provides an entire ecosystem of tools around Metaflow , an open source machine learning infrastructure framework we started, to empower data scientists and machine learning practitioners to build and manage a variety of ML systems. ETL workflows), as well as downstream (e.g.
This site is protected by reCAPTCHA and the Google Privacy Policy and Terms of Service apply.

Tweag
APRIL 26, 2023
Moreover, these steps can be combined in different ways, perhaps omitting some or changing the order of others, producing different data processing pipelines tailored to a particular task at hand. The reader is assumed to be somewhat familiar with the DataKinds and TypeFamilies extensions, but we will review some peculiarities.

Precisely
JULY 25, 2023
Data Integrity Today’s innovators take proactive steps to improve the quality and integrity of their most important data. For those who rely on SAP as the backbone of their business information systems, the integrity of SAP master data is critical. We call these strategic data processes.

Data Engineering Podcast
JULY 27, 2020
Summary A majority of the scalable data processing platforms that we rely on are built as distributed systems. Kyle Kingsbury created the Jepsen framework for testing the guarantees of distributed data processing systems and identifying when and why they break.

Data Engineering Podcast
APRIL 24, 2022
WhyLogs is a powerful library for flexibly instrumenting all of your data systems to understand the entire lifecycle of your data from source to productionized model. You have full control over your data and their plugin system lets you integrate with all of your other data tools, including data warehouses and SaaS platforms.
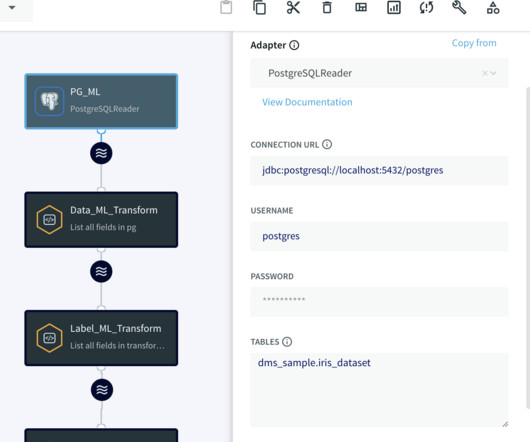
Striim
NOVEMBER 17, 2023
Striim serves as a real-time data integration platform that seamlessly and continuously moves data from diverse data sources to destinations such as cloud databases, messaging systems, and data warehouses, making it a vital component in modern data architectures.

Expert insights. Personalized for you.



































Let's personalize your content