

Apache Spark MLlib vs Scikit-learn: Building Machine Learning Pipelines
Towards Data Science
MARCH 9, 2023
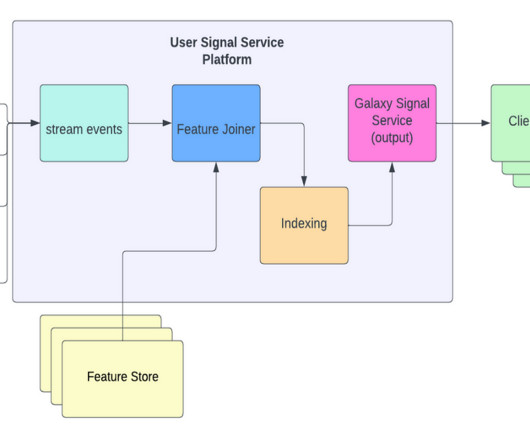
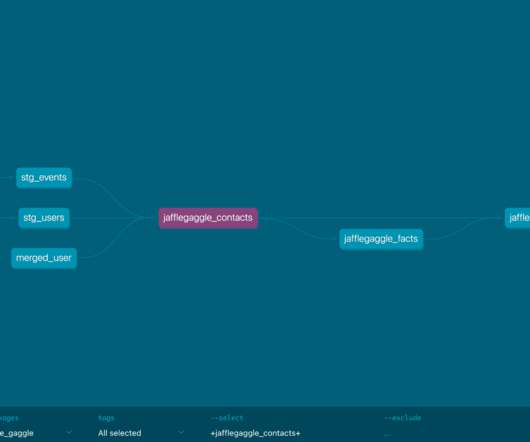
Although within a big data context, Apache Spark’s MLLib tends to overperform scikit-learn due to its fit for distributed computation, as it is designed to run on Spark. Datasets containing attributes of Airbnb listings in 10 European cities ¹ will be used to create the same Pipeline in scikit-learn and MLLib. Source: The author.


































Let's personalize your content