
2. Diving Deeper into Psyberg: Stateless vs Stateful Data Processing
Netflix Tech
NOVEMBER 14, 2023
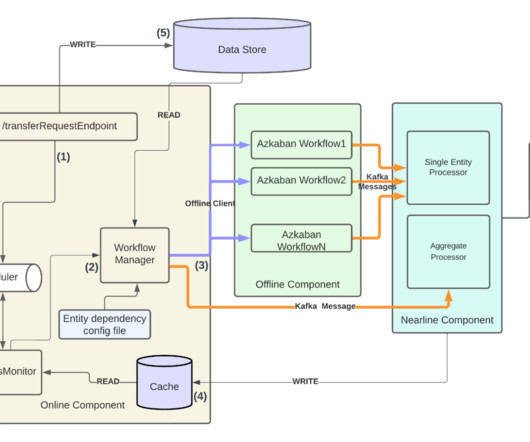
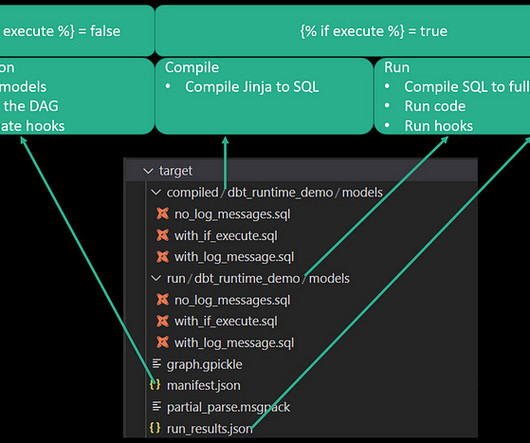
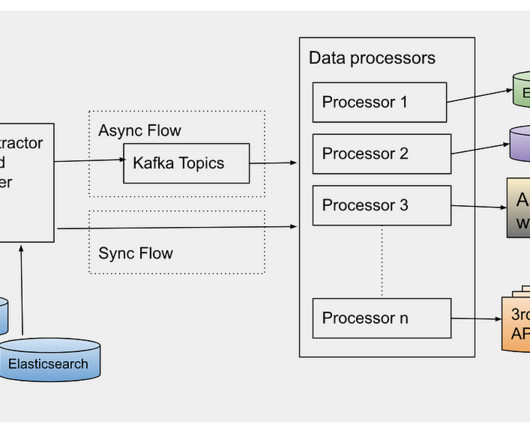
By Abhinaya Shetty , Bharath Mummadisetty In the inaugural blog post of this series, we introduced you to the state of our pipelines before Psyberg and the challenges with incremental processing that led us to create the Psyberg framework within Netflix’s Membership and Finance data engineering team.







































Let's personalize your content