

LLM finetuning memory requirements by Alex Birch
Scott Logic
NOVEMBER 23, 2023
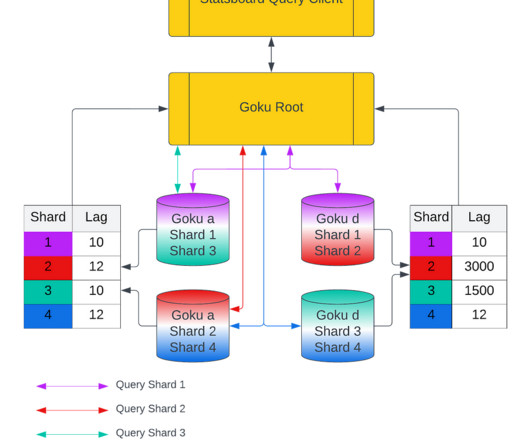
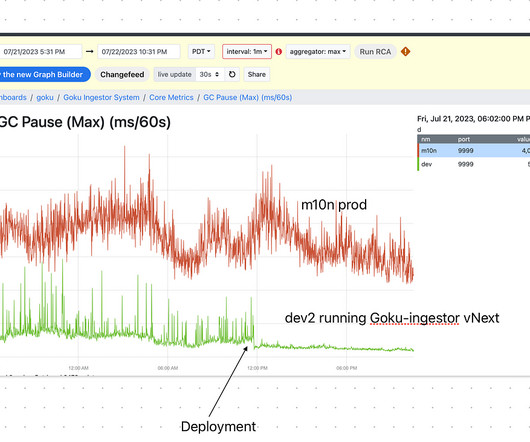
Cost increases when gradient accumulation is enabled, or becomes ~free if used in concert with DDP DDP usually costs ~4 bytes/param, but becomes cheaper if used in concert with AMP DDP can be made 2.5 Transformer Math does not mention a "4 bytes/param master gradients" cost.





































Let's personalize your content