
Integrating Striim with BigQuery ML: Real-time Data Processing for Machine Learning
Striim
NOVEMBER 17, 2023
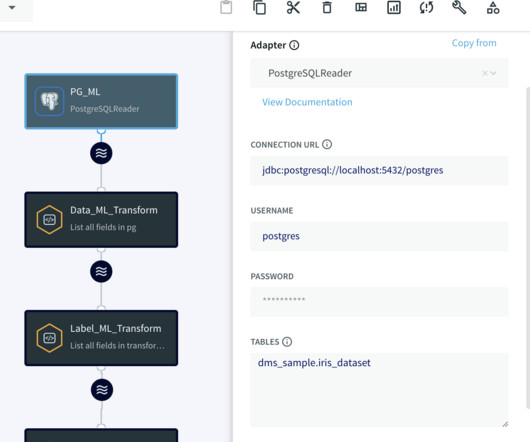
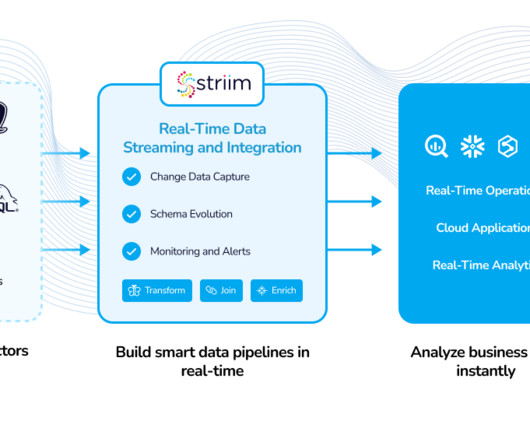
Real-time data processing in the world of machine learning allows data scientists and engineers to focus on model development and monitoring. Striim’s strength lies in its capacity to connect to over 150 data sources, enabling real-time data acquisition from virtually any location and simplifying data transformations.












































Let's personalize your content