
Simplifying BI pipelines with Snowflake dynamic tables
ThoughtSpot
MARCH 5, 2024
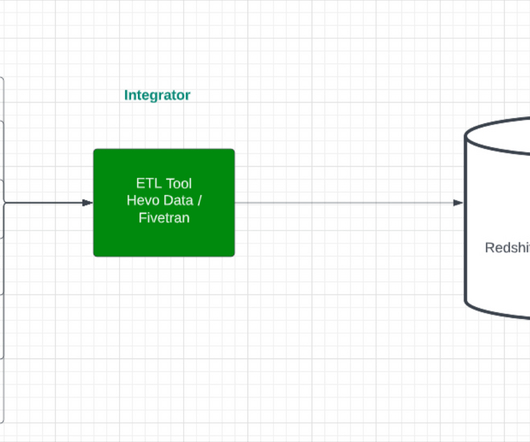
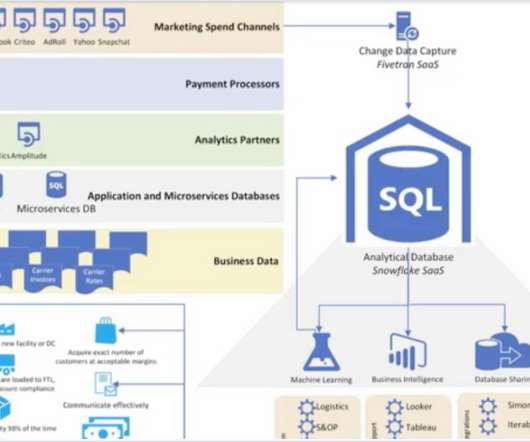
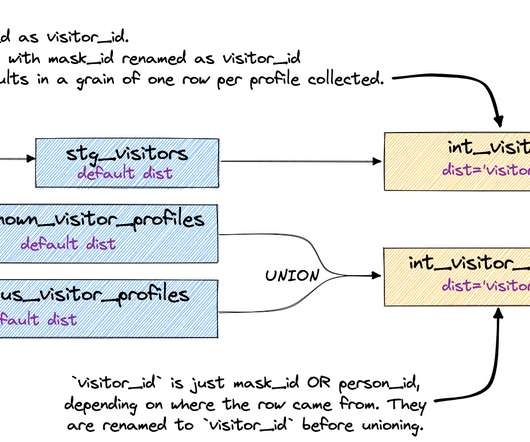
When created, Snowflake materializes query results into a persistent table structure that refreshes whenever underlying data changes. These tables provide a centralized location to host both your raw data and transformed datasets optimized for AI-powered analytics with ThoughtSpot. Set refresh schedules as needed.










































Let's personalize your content