

Shuffle in PySpark
Waitingforcode
FEBRUARY 3, 2023
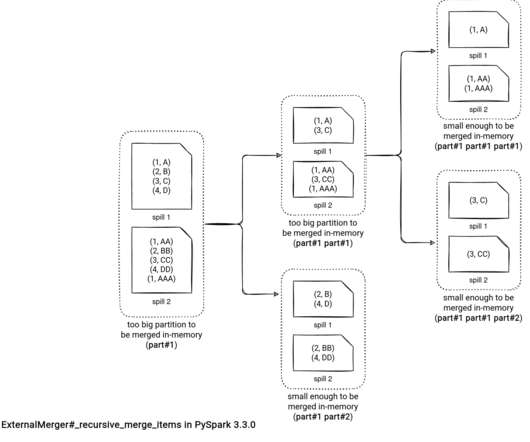
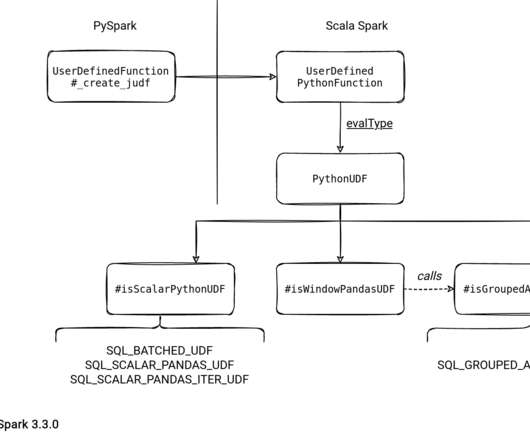
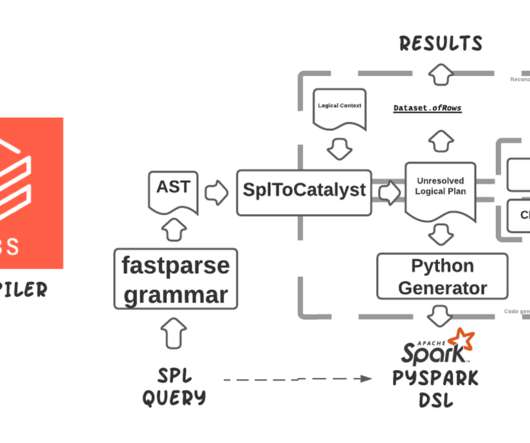
My recent PySpark investigation led me to the shuffle.py file and my first reaction was "Oh, so PySpark has its own shuffle mechanism?". Last year I spent long weeks analyzing the readers and writers and was hoping for some rest in 2022. However, it didn't happen. Let's check this out!











































Let's personalize your content