

Mainframe Optimization: 5 Best Practices to Implement Now
Precisely
JANUARY 25, 2024
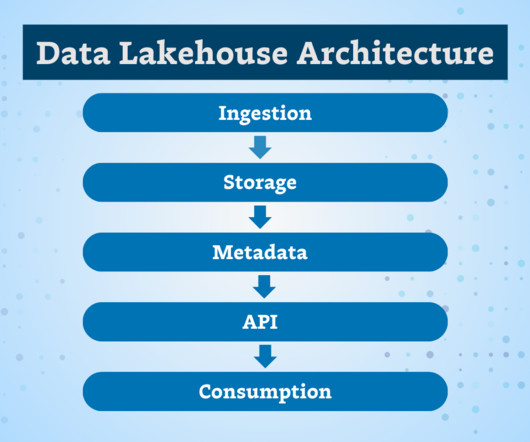
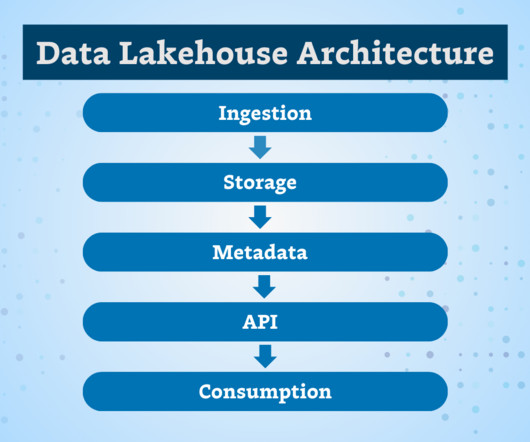
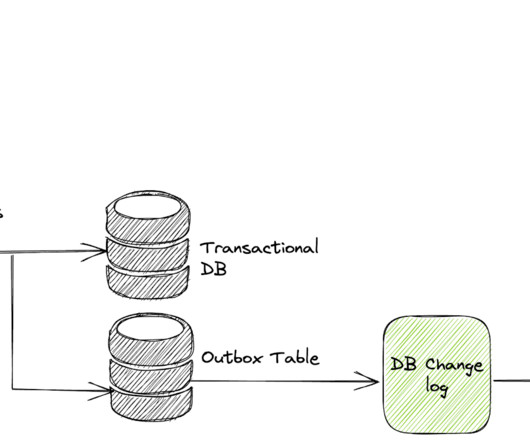
It frequently also means moving operational data from native mainframe databases to modern relational databases. Typically, a mainframe to cloud migration includes re-factoring code to a modern object-oriented language such as Java or C# and moving to a modern relational database. Best Practice 2. Best Practice 3.








































Let's personalize your content