

5 Helpful Extract & Load Practices for High-Quality Raw Data
Meltano
DECEMBER 7, 2022
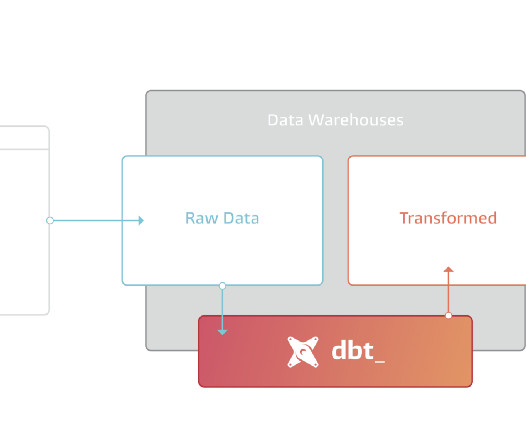
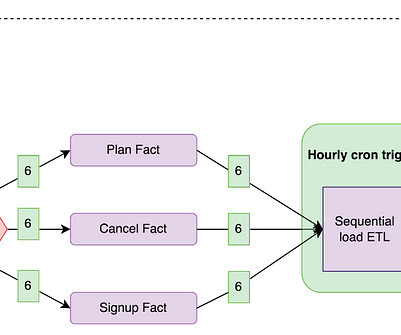
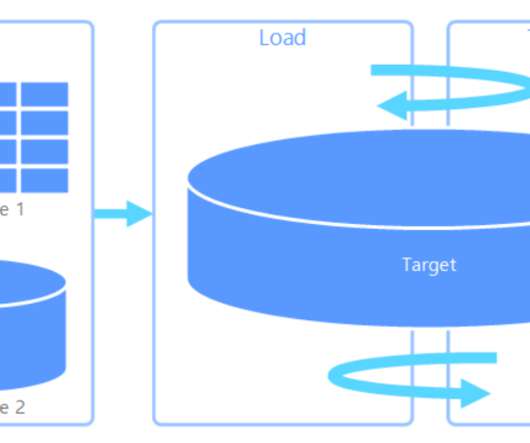
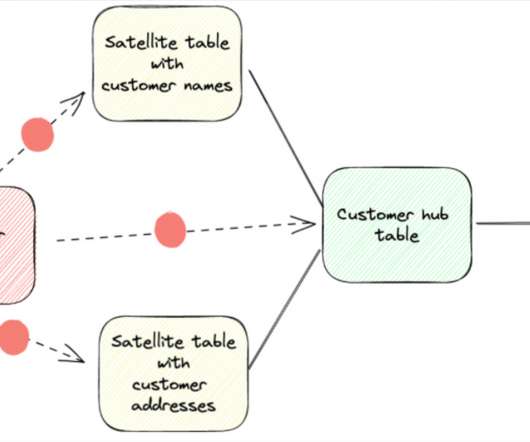
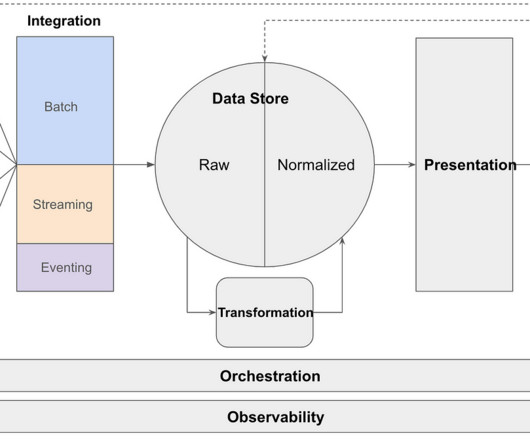
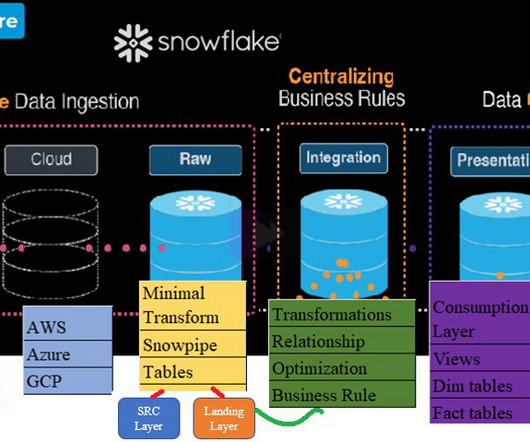
Setting the Stage: We need E&L practices, because “copying raw data” is more complex than it sounds. For instance, how would you know which orders got “canceled”, an operation that usually takes place in the same data record and just “modifies” it in place. But not at the ingestion level.








































Let's personalize your content