
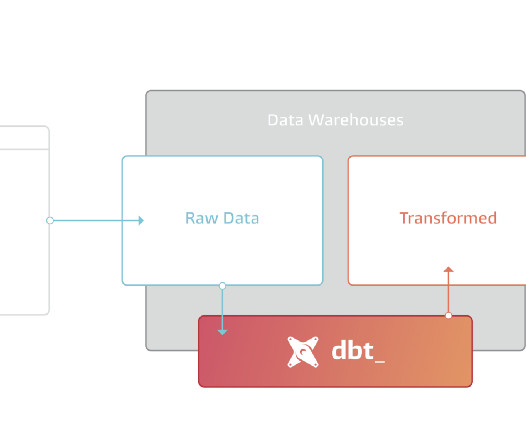
How to get started with dbt
Christophe Blefari
MARCH 1, 2023
This switch has been lead by modern data stack vision. In terms of paradigms before 2012 we were doing ETL because storage was expensive, so it became a requirement to transform data before the data storage—mainly a data warehouse, to have the most optimised data for querying.





































Let's personalize your content