
A Definitive Guide to Using BigQuery Efficiently
Towards Data Science
MARCH 5, 2024
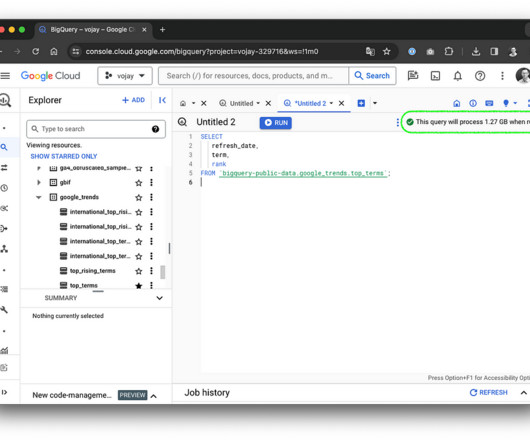
The storage system is using Capacitor, a proprietary columnar storage format by Google for semi-structured data and the file system underneath is Colossus, the distributed file system by Google. In that case, queries are still processed using the BigQuery compute infrastructure but read data from GCS instead.
































Let's personalize your content