

Apache Spark vs MapReduce: A Detailed Comparison
Knowledge Hut
MAY 2, 2024
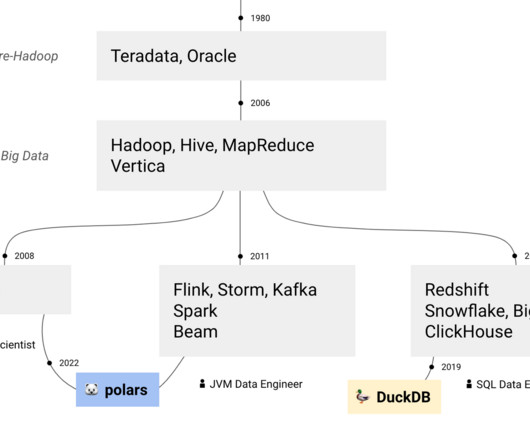
Why We Need Big Data Frameworks Big data is primarily defined by the volume of a data set. Big data sets are generally huge – measuring tens of terabytes – and sometimes crossing the threshold of petabytes. It is surprising to know how much data is generated every minute. As estimated by DOMO : Over 2.5











































Let's personalize your content