

Top 8 Hadoop Projects to Work in 2024
Knowledge Hut
DECEMBER 28, 2023
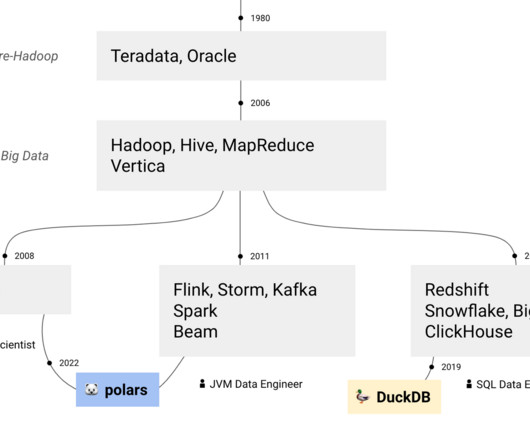
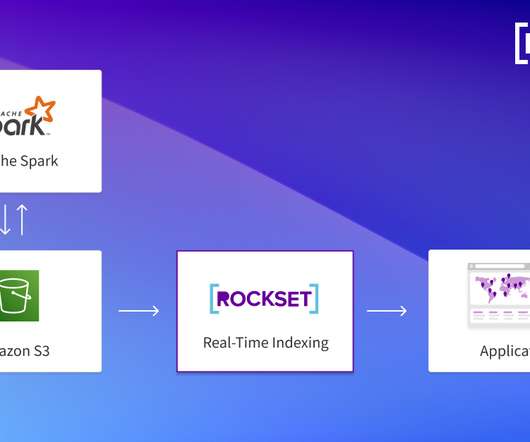
That's where Hadoop comes into the picture. Hadoop is a popular open-source framework that stores and processes large datasets in a distributed manner. Organizations are increasingly interested in Hadoop to gain insights and a competitive advantage from their massive datasets. Why Are Hadoop Projects So Important?











































Let's personalize your content