

A Cost-Effective Data Warehouse Solution in CDP Public Cloud – Part1
Cloudera
FEBRUARY 9, 2021
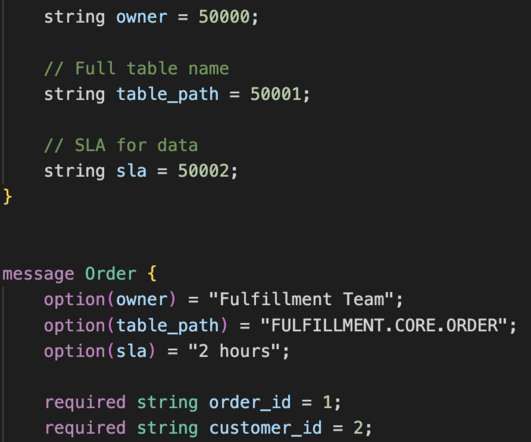
Ingesting into cloud storage directly is independent of any data warehouse compute services, which resolves a common issue in the traditional data warehouse that ETL jobs and analysis queries very often compete against each other for resources. The history data is always required for certain industry regulatory compliance.












Let's personalize your content