
Implementing Data Contracts in the Data Warehouse
Monte Carlo
JANUARY 25, 2023
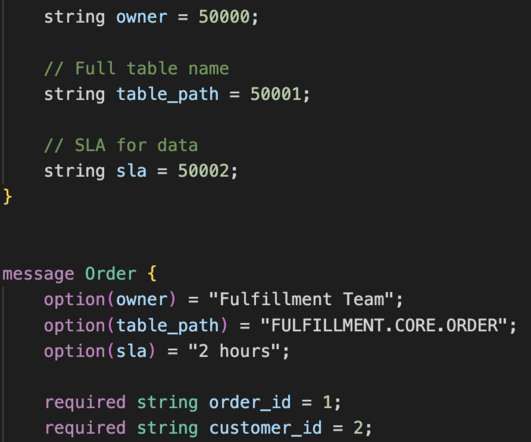
The contracts themselves should be created using well-established protocols for serializing and deserializing structured data such as Google’s Protocol Buffers (protobuf), Apache Avro, or even JSON. We can specify the fields of the contract in addition to metadata like ownership, SLA, and where the table is located.










Let's personalize your content