

Large Scale Ad Data Systems at Booking.com using the Public Cloud
Booking.com Engineering
DECEMBER 2, 2022
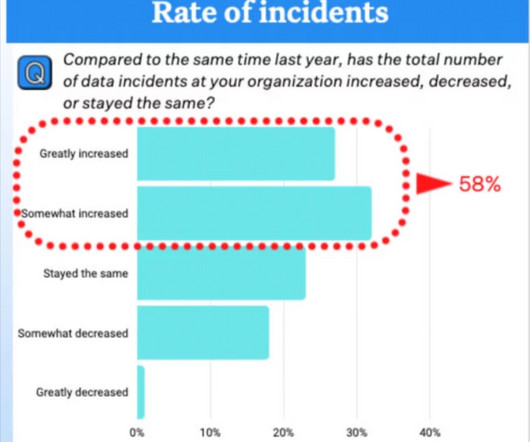
BigQuery also offers native support for nested and repeated data schema[4][5]. We take advantage of this feature in our ad bidding systems, maintaining consistent data views from our Account Specialists’ spreadsheets, to our Data Scientists’ notebooks, to our bidding system’s in-memory data.














Let's personalize your content