

Practical Magic: Improving Productivity and Happiness for Software Development Teams
LinkedIn Engineering
DECEMBER 19, 2023
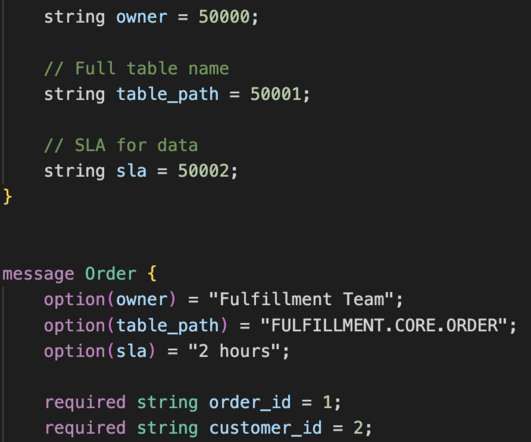
Co-authors: Max Kanat-Alexander and Grant Jenks Today we are open-sourcing the LinkedIn Developer Productivity & Happiness Framework (DPH Framework) - a collection of documents that describe the systems, processes, metrics, and feedback systems we use to understand our developers and their needs internally at LinkedIn.
























Let's personalize your content