
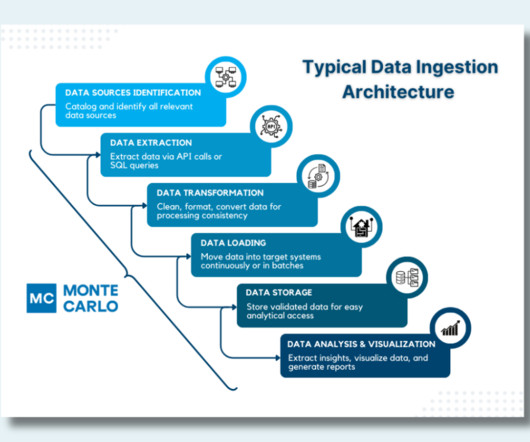
How to Design a Modern, Robust Data Ingestion Architecture
Monte Carlo
MAY 28, 2024
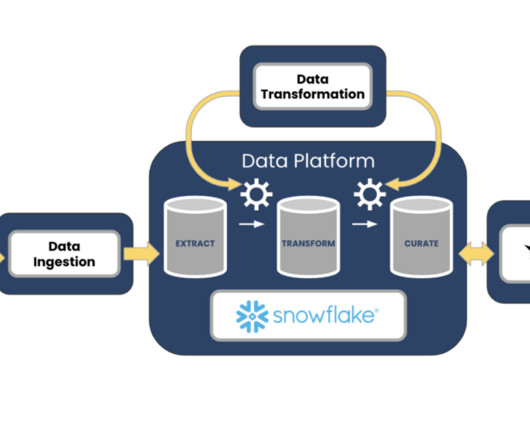
This involves connecting to multiple data sources, using extract, transform, load ( ETL ) processes to standardize the data, and using orchestration tools to manage the flow of data so that it’s continuously and reliably imported – and readily available for analysis and decision-making.












































Let's personalize your content