

Tips to Build a Robust Data Lake Infrastructure
DareData
JULY 5, 2023
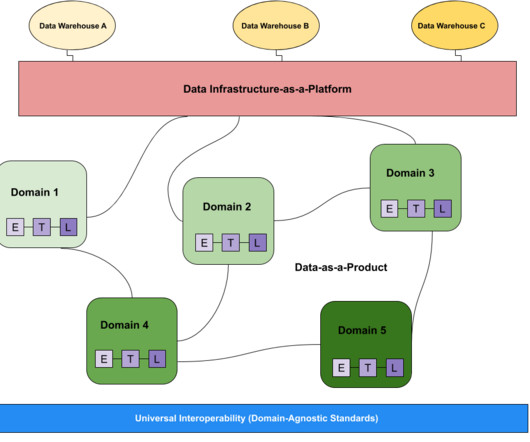
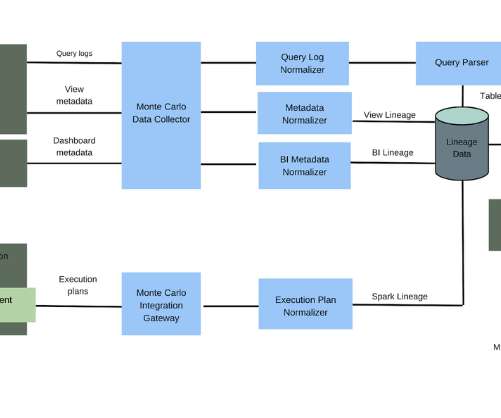
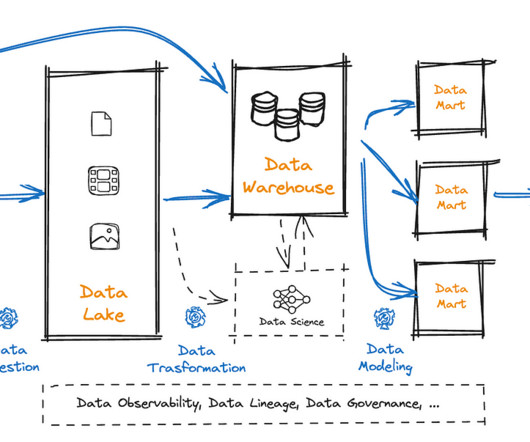
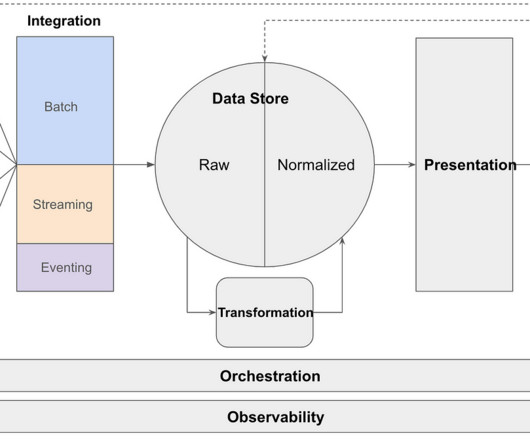
Learn how we build data lake infrastructures and help organizations all around the world achieving their data goals. In today's data-driven world, organizations are faced with the challenge of managing and processing large volumes of data efficiently. And what is the reason for that?













































Let's personalize your content