

Data Warehouse vs Data Lake vs Data Lakehouse: Definitions, Similarities, and Differences
Monte Carlo
AUGUST 25, 2023
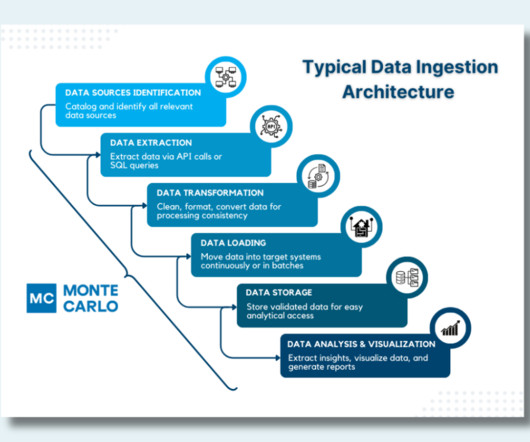
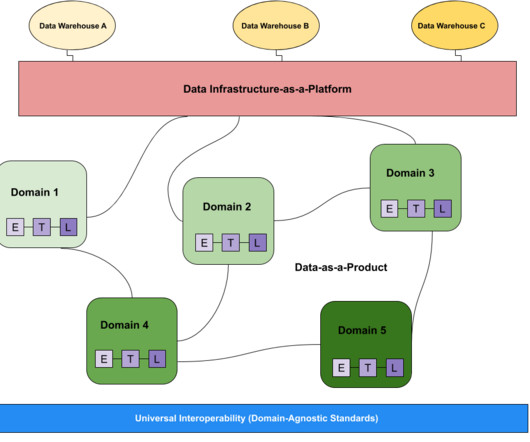
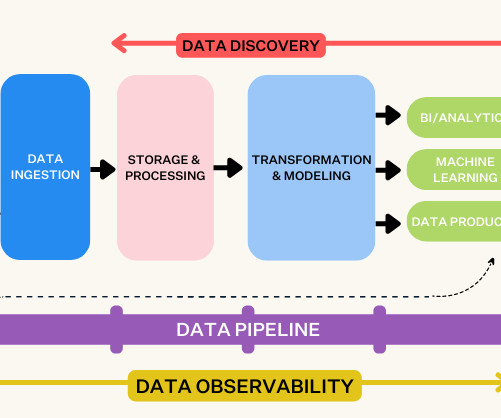
That’s why it’s essential for teams to choose the right architecture for the storage layer of their data stack. But, the options for data storage are evolving quickly. So let’s get to the bottom of the big question: what kind of data storage layer will provide the strongest foundation for your data platform?






































Let's personalize your content