


Introducing a Cloud-Native Experience for Apache Kafka in Confluent Cloud
Confluent
MAY 13, 2019
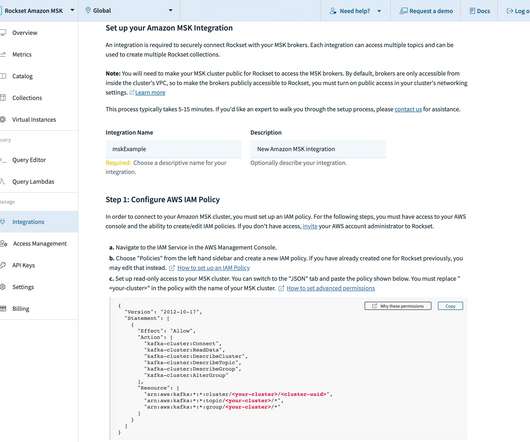
In the last year, we’ve experienced enormous growth on Confluent Cloud, our fully managed Apache Kafka ® service. As Confluent Cloud has grown, we’ve noticed two gaps that very clearly remain to be filled in managed Apache Kafka services. Five seconds to Kafka (or, never make another cluster again!).





































Let's personalize your content