

How to get datasets for Machine Learning?
Knowledge Hut
APRIL 26, 2024
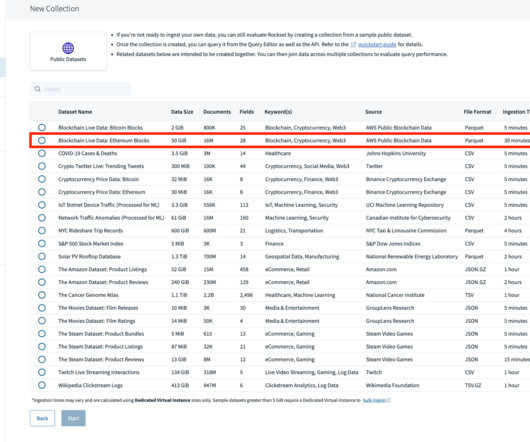
Datasets are the repository of information that is required to solve a particular type of problem. Datasets play a crucial role and are at the heart of all Machine Learning models. Datasets are often related to a particular type of problem and machine learning models can be built to solve those problems by learning from the data.










































Let's personalize your content