

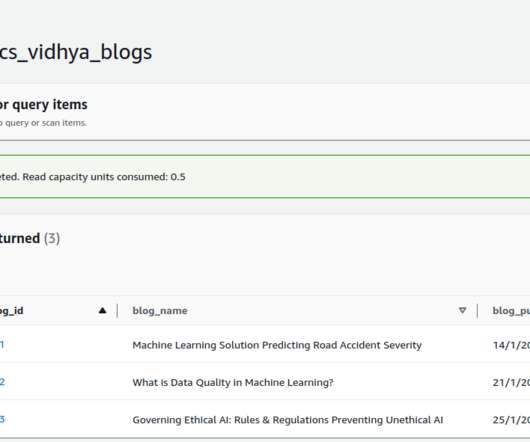
How to Implement a Data Pipeline Using Amazon Web Services?
Analytics Vidhya
FEBRUARY 6, 2023
Introduction The demand for data to feed machine learning models, data science research, and time-sensitive insights is higher than ever thus, processing the data becomes complex. To make these processes efficient, data pipelines are necessary. appeared first on Analytics Vidhya.
































Let's personalize your content