

Best Practices for Data Ingestion with Snowflake: Part 3
Snowflake
APRIL 19, 2023
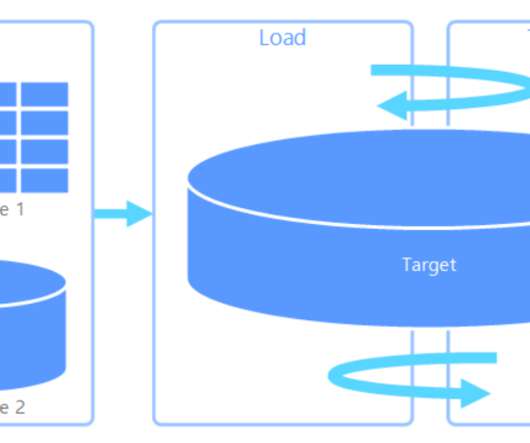
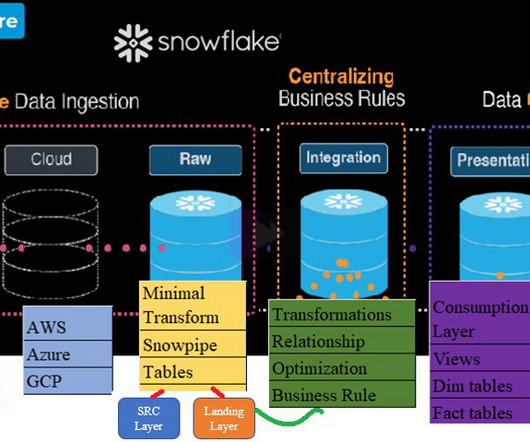
Welcome to the third blog post in our series highlighting Snowflake’s data ingestion capabilities, covering the latest on Snowpipe Streaming (currently in public preview) and how streaming ingestion can accelerate data engineering on Snowflake. What is Snowpipe Streaming?













































Let's personalize your content