


How to use the DockerOperator
Marc Lamberti
OCTOBER 11, 2023
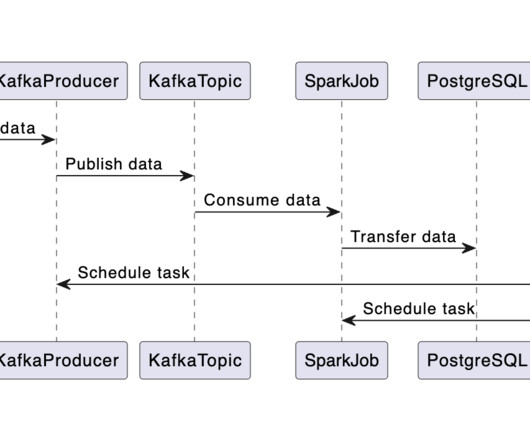
Do you wonder how to use the DockerOperator in Airflow to kick off a docker image? The DockerOperator allows you to run Docker Containers that correspond to your tasks, packed with their required dependencies and isolated from the rest of your Airflow environment. The Docker Container succeeds or fails (your task).

























Let's personalize your content