

Apache Kafka Deployments and Systems Reliability – Part 1
Cloudera
SEPTEMBER 20, 2021
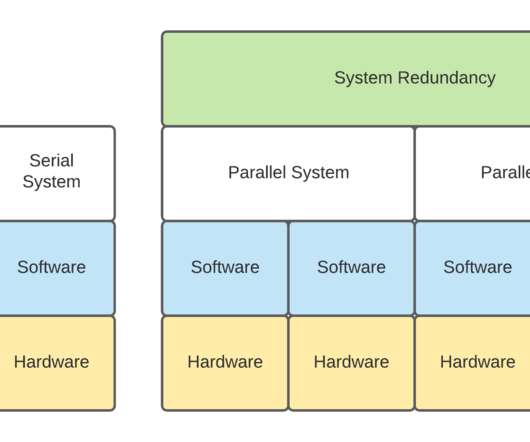
There are many ways that Apache Kafka has been deployed in the field. In our Kafka Summit 2021 presentation, we took a brief overview of many different configurations that have been observed to date. Serial and Parallel Systems Reliability . Serial Systems Reliability.




































Let's personalize your content