

Centralize Your Data Processes With a DataOps Process Hub
DataKitchen
NOVEMBER 4, 2021
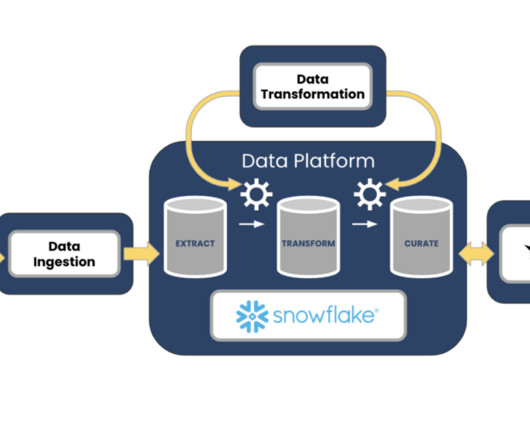
The typical pharmaceutical organization faces many challenges which slow down the data team: Raw, barely integrated data sets require engineers to perform manual , repetitive, error-prone work to create analyst-ready data sets. Cloud computing has made it much easier to integrate data sets, but that’s only the beginning.


































Let's personalize your content